|
Dear friends,
Ever wonder how we write this newsletter?
The team behind The Batch includes Ted Greenwald, a former Wall Street Journal editor. Every week our team meets to discuss the most important news items, papers, and breakthroughs. Then we obsessively summarize them as concisely as possible to maximize how quickly you can read them.

Our average article length is ~300 words, compared to the typical newspaper article length of 1000+ words. I hope The Batch is becoming a useful part of your week!
Please let us know how we can make The Batch even more useful to you by sending us a note at thebatch@deeplearning.ai.
Keep learning!
Andrew
deeplearning.ai Exclusive
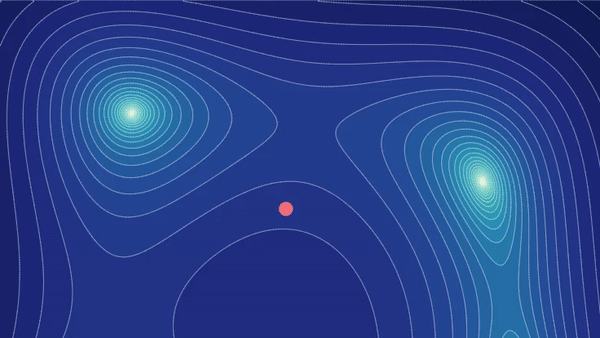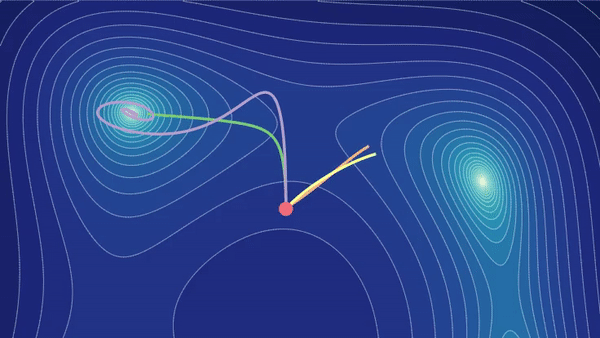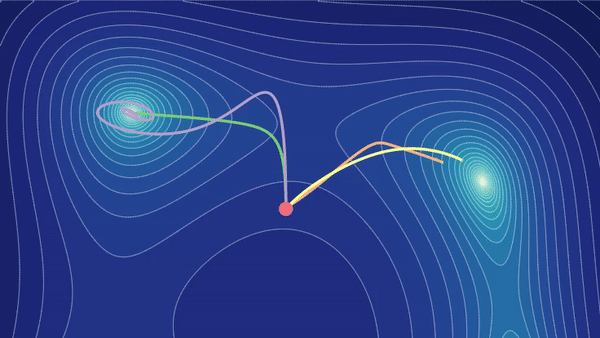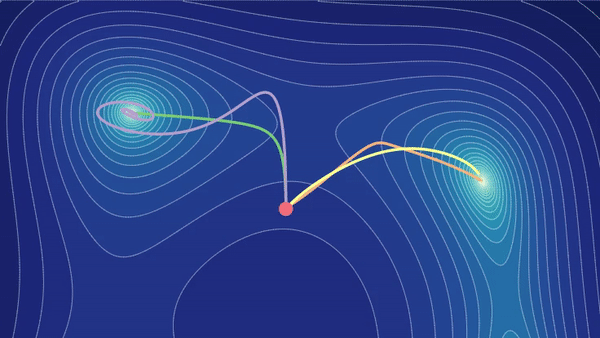
Tutorial: Parameter Optimization
Training a machine learning model is a matter of closing the gap between the model's predictions and the training data labels. But optimizing a model's parameters isn't so straightforward. Through interactive visualizations, we'll help you develop your intuition for setting up and solving this optimization problem. Learn more
News
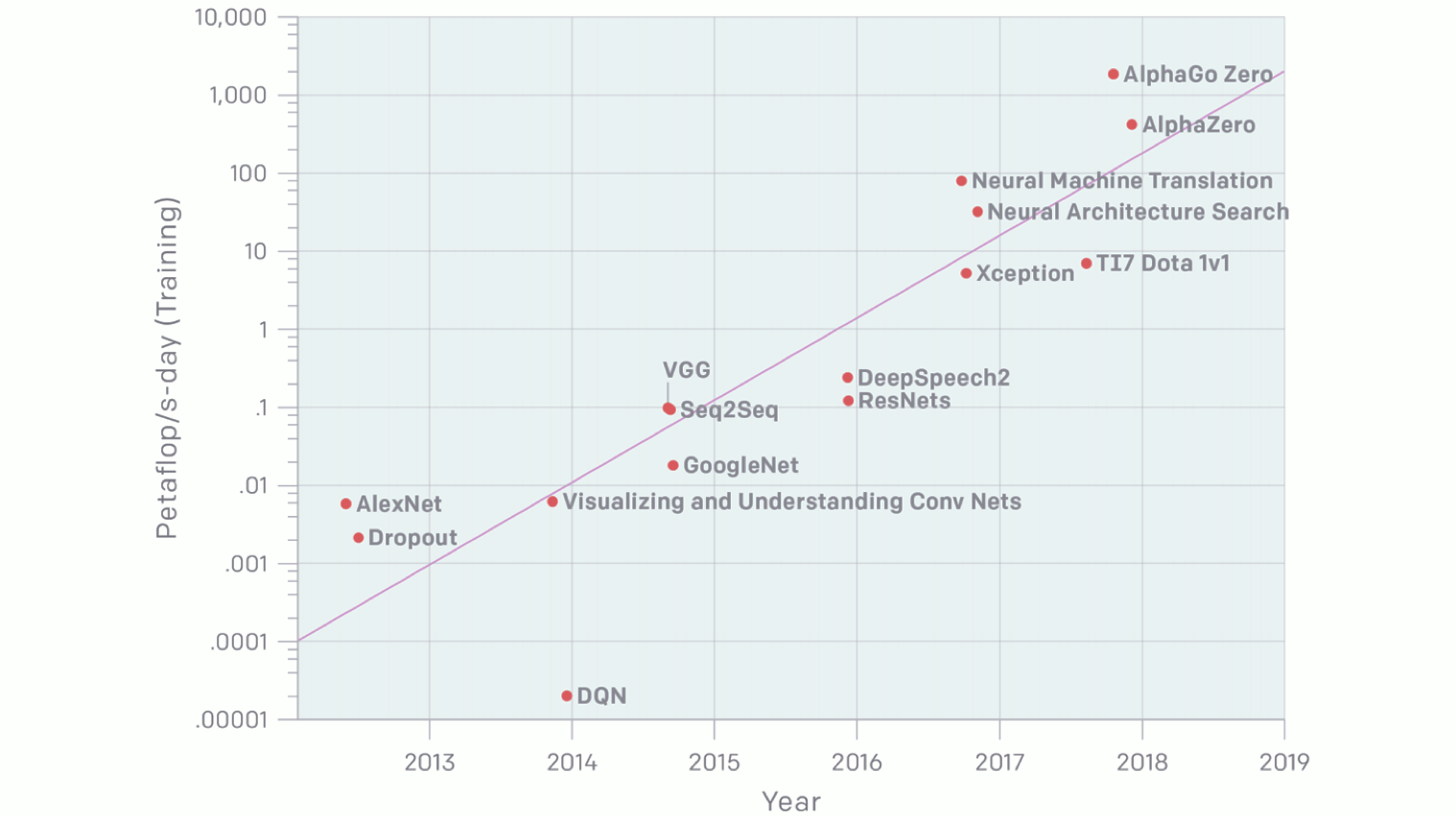
The Greening of AI
Training state-of-the-art models consumes ever more energy and releases ever more greenhouse gas, a rising contributor to climate change — not to mention a limiting factor on AI innovation. A new study proposes guidelines for cutting AI’s carbon footprint.
What’s new: A report from the Allen Institute for Artificial Intelligence argues that, for new models, energy efficiency is as important as accuracy. The report sets forth several ways to assess AI's carbon emissions.
The analysis: The authors sampled 60 papers from three top AI conferences. Their conclusions:
- 80 percent of papers claim greater accuracy as their biggest contribution, rather than better efficiency in terms of speed or model size.
- The total energy cost of producing a model increases linearly with each of three variables: the size of its training data set, the number of hyperparameter experiments, and the monetary cost of executing the model on a single example.
- The authors recommend that developers report energy consumption per model. The authors recommend reporting floating point operations per second, which reflects directly the computational work to run a specific model.
Behind the news: Some AI companies say they've gone green already. Google says its AI operations run completely on renewables, while Amazon claims its overall operations run 50 percent on renewables.
AI's carbon footprint: In a recent paper, researchers concluded that training the average deep learning model using fossil fuel releases around 78,000 pounds of carbon. That’s more than half of a car's output from assembly line to landfill.
We’re thinking: Engineers already have a challenging job building accurate models. As a practical matter, many teams will focus first on accuracy and, once they have a working product, work on driving up energy efficiency.
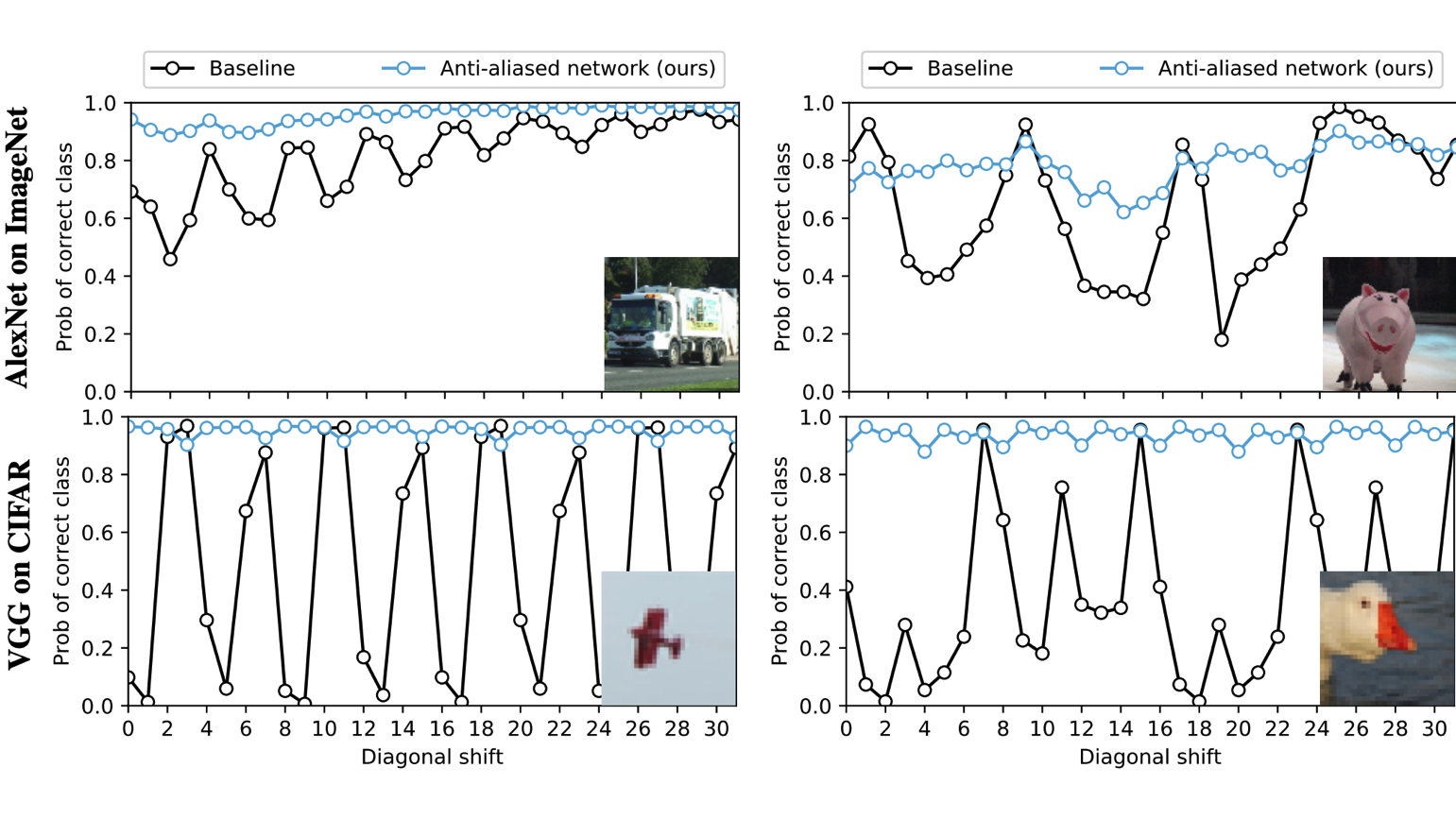
Shifted Data? No Problem!
Offset an image by one pixel, and a convolutional network with sampling layers may classify it differently. New research takes a big step toward solving the problem.
What’s new: Richard Zhang of Adobe proposes in a new paper replacement layers that largely alleviate the issue known as shift variance.
Key insight: Zhang decomposed each of three common sampling operations — max, average, or sub-sampling — in pooling layers and designed a shift-invariant alternative for each one. His solutions are inspired by the Nyquist-Shannon Sampling Theorem, a formula long used in signal processing to compensate for small alterations in input.
How it works: Zhang proposes substitute layers for max pooling, average pooling, and strided convolutions: MaxBlurPool, BlurPool, and ConvBlurPool. The output of these layers is much less sensitive to shifted input, but still not perfectly shift-invariant.
- Max pooling and average pooling trip over shifted input when the sampling windows don't overlap. Overlapping the windows and subsampling from them produces output identical to the usual approach, but it's easier to modify to be robust to shifted input.
- MaxBlurPool uses overlapping max pooling windows. However, instead of directly subsampling the values, it blurs the max values before subsampling.
- BlurPool replaces average pooling by blurring each window where an average would be taken.
- Strided convolutions misrepresent shifted input because they skip pixels. ConvBlurPool produces output of the same size but is less vulnerable to shifted input by (a) blurring in windows sized to match the stride and then (b) applying the same convolutional filter to the blurred input with no stride.
Results: Zhang's layers boosted ImageNet accuracy by up to 2 percent using ResNet, VGG, and DenseNet. Hidden units in each network layer are largely shift-invariant in those architectures.
Why it matters: Max pooling and deeper networks perform so well that engineers tend to tolerate problems with shifted input. This research offers a way to get shift-invariance along with the same performance.
We’re thinking: The generality of these methods makes them useful in a wide variety of models, where they could boost performance by a small but significant margin.
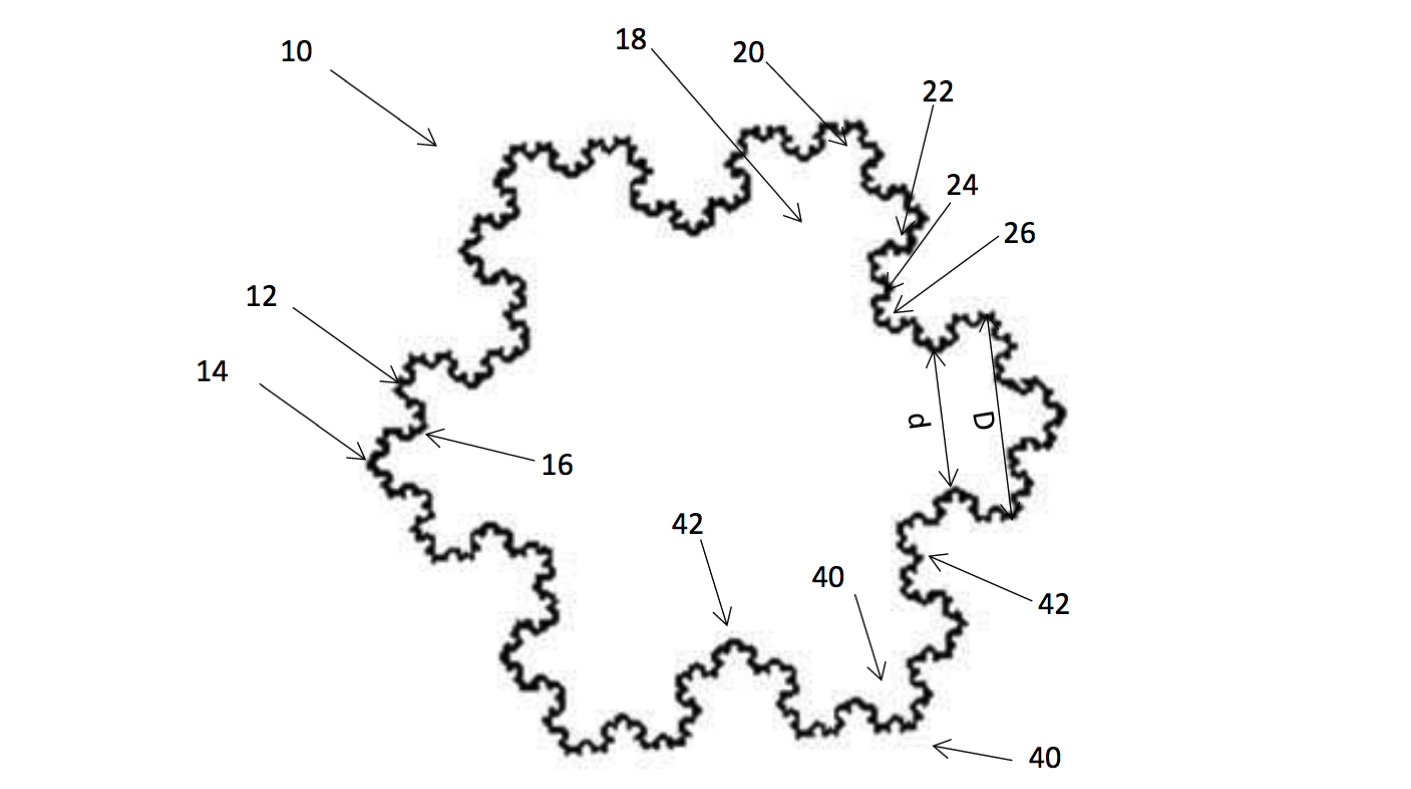
The Edison Machine
Neural networks are producing original news stories, videos, and sonatas. Should they have intellectual property rights?
What's new: Two patent applications under consideration in the U.S., EU, and UK were invented by artificial intelligence. A neural network called Dabus — short for Device for the Autonomous Bootstrapping of Unified Sentience — claims rights to a container “based on fractal geometry” and a “neural flame” that illuminates in times of emergency.
Automated invention: Dabus inventor Stephen Thaler trained the model on text, images, and other data from various domains.
- Perturbation parameters disturb the system's connections between knowledge domains. This prompts the model to form associations.
- A subsystem critiques such associations for novelty, based on Dabus’ training and history of connecting domains.
- When the model settles on a novel idea, Thaler assesses the connections and formalizes the idea into a patent.
- For the fractal container (illustrated above), Dabus connected the concept of a container with the fractal properties of heating and cooling, as well as the concepts of pleasure and convenience. Thaler interpreted the output to make a patent application.
Behind the news: It’s not clear whether AI legally can be awarded patents. UK and EU patent laws limit inventorship to “natural persons.” U.S. rules are less explicit, referring to “individuals.”
Why it matters: Ryan Abbott, a Surrey University law professor, argues that giving creative credit to AI will incentivize investment in what he calls imaginative computing. In his view, the machine should get credit for the invention, which enhances its value, while its owner should get any resulting patents.
What they’re saying: “Whatever you think of the ideas on their own, that’s not really the point,” Abbott says. “What’s striking is that the machine invented in two very different areas, neither of which its programmer had any background in.”
We’re thinking: Don't tell patent trolls about this.
A MESSAGE FROM DEEPLEARNING.AI

What are the key computations that differentiate shallow and deep neural networks? Apply them to computer vision applications in the Deep Learning Specialization.
.gif?upscale=true&name=knitting%20ezgif.com-gif-maker%20(1).gif)
Neural Knits
Knitting machines are crafty and fast, but they don’t have the vast library of designs that help make home-made knitwear so special. A new GAN decodes even the most complex needlework on sight.
What’s new: MIT researchers developed software that transforms photos of fabric into industrial blueprints of the stitches used to produce it.
How it works: Knitting pattern instructions are written with hobbyists in mind. Translating them for machines requires manually typing instructions in low-level code. The researchers developed a shortcut by combining CNN and GAN architectures.
- The authors trained the model to recognize stitches and patterns in a mix of photographs and computer-generated images of garments. The generated images helped the model understand idealized 2D projections of 3D garments, without warping and flattening of the actual garment.
- They fed the model a picture of a pattern they had knitted. The model created an idealized image that was easier than a photo for the computer to read.
- Then, another neural network classified each stitch according to the 17 used in knitting, and it generated a labeled blueprint.
Why it matters: Whole-garment knitting, in which machines produce seamless three-dimensional garments, represents a growing percentage of the $23.8 billion global knitted fabric industry. The trend toward fashion on demand drives much of that growth, but the ability to capture designs could give it an extra push.
We’re thinking: Applied elsewhere, models like this could aid in a variety of design tasks. And home-made knitting will remain as special as ever.
Recommending Rigorous Research
Recommender systems typically use traditional machine learning methods, but a lot of effort has gone into building them with neural networks. A new analysis of the literature reveals that enthusiasm for neural recommenders may be masking poor research practices.
What’s new: Researchers from Politecnico di Milano, Italy, and the University of Klagenfurt, Austria, attempted to test 18 recent neural network models for top-n recommendation. It turns out that only seven are reproducible, and six underperform traditional approaches that don’t use deep learning.
Key Insight: Most researchers demonstrating state-of-the-art performance using neural networks don’t compare their approach to strong baselines. Some compare their work only to previous neural approaches, which may be weaker.
How it works: Authors Maurizio Dacrema, Paolo Cremonesi, and Dietmar Jannach consider a paper reproducible if its source code and a data set used to evaluate it are publicly available, and if the corresponding paper includes enough information to train the model with minimal changes. For the seven papers that meet these criteria, they compared performance to baselines including:
- Most popular item recommendation.
- K-nearest-neighbor similarity on item ratings, user ratings, item content, combination of item ratings and content.
- K-nearest-neighbor similarity on the probability that a user will reach an item in a random walk on a user-item graph.
- SVD for matrix completion.
Results: All neural methods underperform at least one baseline except for MultVAE. The authors also found pervasive problems with the reporting of results. In one paper, researchers set the number of training epochs based on performance with the test set rather than the validation set. In another, they used a test set selected to yield favorable results while claiming a random split.
Takeaway: The goal of science is to acquire knowledge, not to chalk a victory with each new approach. Results must stack up against established baselines and have little meaning if they’re not reproducible. The ICLR Reproducibility Challenge sets a solid standard for other venues to emulate.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai.
Subscribe here and add our address to your contacts list so our mailings don't end up in the spam folder. You can unsubscribe from this newsletter or update your preferences here.
Copyright 2019 deeplearning.ai, 195 Page Mill Road, Suite 115, Palo Alto, California 94306, United States. All rights reserved.
|
