|
Dear friends,
AI-enabled automation is often portrayed as a binary on-or-off: A process is either automated or not. But in practice, automation is a spectrum, and AI teams have to choose where on this spectrum to operate. It’s important to weigh the social impact of our work, and we must ameliorate automation’s impact on jobs. In addition to this important consideration, the best choice often depends on the application and what AI can and cannot do.
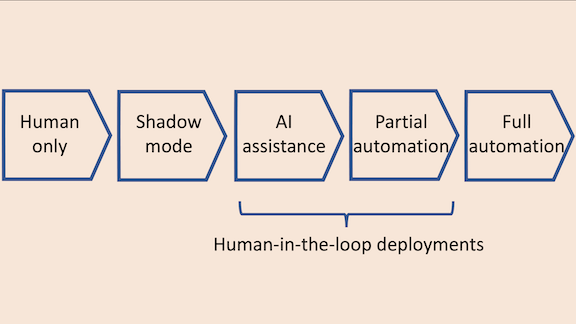
Take the problem of diagnosing medical patients from X-rays. The deployment options include:
- Human only: No AI involved.
- Shadow mode: A human doctor reads an X-ray and decides on a diagnosis, but an AI system shadows the doctor with its own attempt. The system’s output doesn’t create value for doctors or patients directly, but it is saved for analysis to help a machine learning team evaluate the AI’s performance before dialing it up to the next level of automation.
- AI assistance: A human doctor is responsible for the diagnosis, but the AI system may supply suggestions. For example, it can highlight areas of an X-ray for the doctor to focus on.
- Partial automation: An AI system looks at an X-ray image and, if it has high confidence in its decision, renders a diagnosis. In cases where it’s not confident, it asks a human to make the decision.
- Full automation: AI makes the diagnosis.
These options can apply to medical diagnosis, visual inspection, autonomous navigation, media content moderation, and many other tasks. In many cases, I’ve found that picking the right one is critical for a successful deployment, and that using either too much or too little automation can have a significant negative impact.
When you’re choosing a point along the automation spectrum, it’s worth considering what degree of automation is possible given the AI system’s accuracy, availability of humans to assist with the task, and desired rate of decision making (for example, human-in-the-loop options won’t work if you need to select an ad to place on a webpage within 100 milliseconds). Today’s algorithms are good enough only for certain points on the spectrum in a given application. As an AI team gains experience and collects data, it might gradually move to higher levels of automation within ethical and legal boundaries.
Some people say that we should focus on IA (intelligence augmentation) rather than AI — that AI should be used to help humans perform tasks rather than automate those tasks. I believe we should try to create value for society overall. Automation can transform and create jobs (as when taxi cabs created new opportunities for cab drivers) as well as destroy them. Even as we pick a point on this spectrum, let’s take others’ livelihoods into account and create value that is widely and fairly shared.
Keep learning!
Andrew
News

Cutting Corners to Recognize Faces
Datasets for training face recognition models have ballooned in size — while slipping in quality and respect for privacy.
What’s new: In a survey of 130 datasets compiled over the last four decades, Mozilla fellow Inioluwa Deborah Raji and AI consultant Genevieve Fried traced how the need for increasing quantities of data led researchers to relax their standards. The result: datasets riddled with blurred photos, biased labels, and images of minors, collected and used without permission, the authors told MIT Technology Review.
What they found: The study divides the history of face datasets into four periods.
- Starting in 1964, face images were captured in photo shoots using paid models and controlled lighting. Gathering these datasets was expensive and time-consuming; the biggest comprised 7,900 images.
- The U.S. Department of Defense kicked off the second period in 1996 by spending $6.5 million to develop FERET, which contained 14,126 images of 1,200 individuals. Like most other datasets of this era, it was compiled from photo shoots with consenting subjects. Models trained on these datasets faltered in the real world partly due to their relatively homogenous lighting and poses.
- Released in 2007, Labeled Faces in the Wild was the first face dataset scraped from the web. LFW’s 13,000 images included varied lighting conditions, poses, and facial expressions. Other large datasets were gathered from Google, Flickr, and Yahoo as well as mugshots and surveillance footage.
- In 2014, Facebook introduced DeepFace, the first face recognition model that used deep learning, which identified people with unprecedented accuracy. Researchers collected tens of millions of images to take advantage of this data-intensive approach. Obtaining consent for every example became impossible, as did ensuring that each one’s label was accurate and unbiased.
Why it matters: People deserve to be treated fairly and respectfully by algorithms as well as other people. Moreover, datasets assembled without due attention to permission and data quality erode the public’s trust in machine learning. Companies like Clearview.ai and FindFace stand accused of harvesting online images without consent and using them in ways that violate individuals’ privacy, while shaky algorithms have contributed to biased policing. In the U.K., Canada, and certain U.S. jurisdictions, lawmakers and lawsuits are calling for restrictions on the use of face images without consent.
We’re thinking: Andrew and his teams have worked on many face recognition systems over the years. Our practices have evolved — and continue to do so — as both society and AI practitioners have come to recognize the importance of privacy. As we gather data, we must also work toward fairer and more respectful standards governing its collection, documentation, and use.
Fun fact: Andrew’s face appears (with permission!) in a Carnegie Mellon University face dataset collected by Tom Mitchell in 1996. Here’s what Andrew looked like in those days.
Bigger, Faster Transformers
Performance in language tasks rises with the size of the model — yet, as a model’s parameter count rises, so does the time it takes to render output. New work pumps up the number of parameters without slowing down the network.
What’s new: William Fedus, Barret Zoph, and Noam Shazeer at Google Brain developed the Switch Transformer, a large-scale architecture (the authors built a version comprising 1.6 trillion parameters) that’s nearly as fast as a much smaller model.
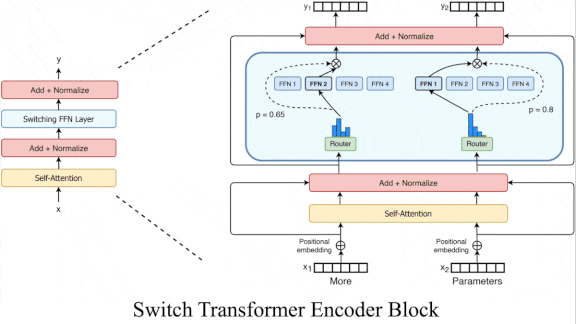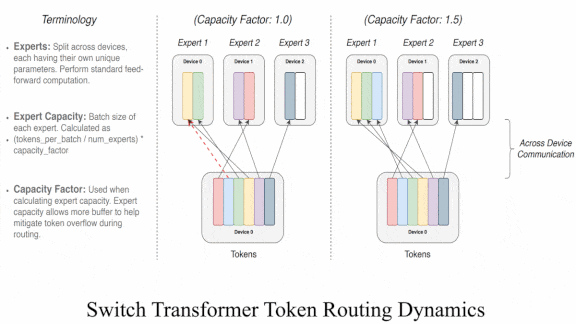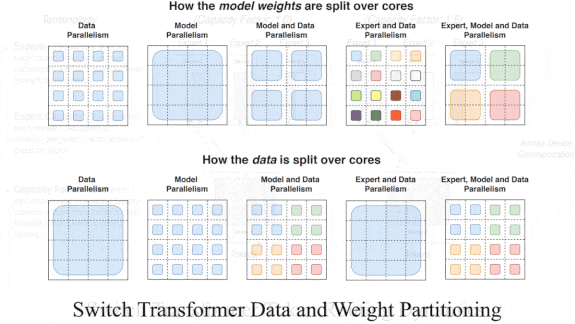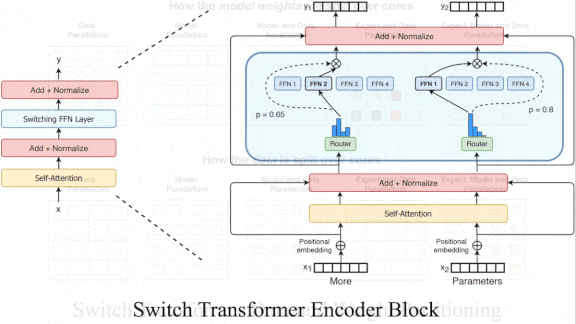
Key insight: The approach known as mixture-of-experts uses only a subset of a model’s parameters per input example. Like mixture-of-experts, Switch Transformer chooses which of many layers would best process a given input.
How it works: The authors trained Switch Transformer to predict words that had been removed at random from a large text dataset scraped from the web. The dataset was preprocessed to remove offensive language, placeholder text, and other issues.
- A typical transformer extracts a representation from each input token, such as a word, and then uses self-attention to compare the representations before passing them to a fully connected layer. Switch Transformer replaces the fully connected layer with one of a number (determined by a hyperparameter) of fully connected layers.
- A softmax layer calculates the probability that any particular fully connected layer is best for processing a given token. Then it uses the chosen layer in the usual manner.
- The fully connected layers process tokens in parallel. The authors added a loss to encourage them to be equally active. On a hardware chip, a separate processor core handles each layer, so this loss encourages equal distribution of the load on each core.
Results: The authors compared Switch Transformer (7.4 billion parameters) to T5 (223 million parameters), a variant similar to the original transformer that was trained on the same dataset, using negative log perplexity, a measure of the model’s uncertainty (higher is better). The new model achieved -1.561 negative log perplexity compared to T5’s -1.731. Switch Transformer ran at two-thirds the speed of T5 — it executed 1,000 predictions per second compared to T5’s 1,600 — with 33 times the number of parameters. It beat a mixture-of-experts transformer, presumably of roughly the same size, on both counts.
Why it matters: In deep learning, bigger is better — but so is a manageable computation budget.
We’re thinking: Transformers come in an increasing variety of flavors. We hope this summary helps you remember which is switch.

Human Disabilities Baffle Algorithms
Facebook’s content moderation algorithms block many advertisements aimed at disabled people.
What’s new: The social media platform’s automated systems regularly reject ads for clothing designed for people with physical disabilities. The algorithms have misread such messages as pornography or sales pitches for medical devices, The New York Times reported.
How it works: Automated systems at Facebook and Instagram examines the images and words in ads that users try to place on the sites. They turn down ads they deem to violate their terms of service. The system tells would-be ad buyers when it rejects their messages, but not why, making it difficult for advertisers to bring rejected materials into compliance. Companies can appeal rejections, but appeals often are reviewed by another AI system, creating a frustrating loop.
- Facebook disallowed an ad for a sweatshirt from Mighty Well bearing the words “I am immunocompromised — please give me space.” The social network’s algorithm had flagged it as a medical product. Mighty Well successfully appealed the decision.
- Facebook and Instagram rejected ads from Slick Chicks, which makes underwear that clasps on the side as a convenience for wheelchair users, saying the ads contained “adult content.” Slick Chicks’ founder appealed the decision in dozens of emails and launched an online petition before Facebook lifted the ban.
- The social-networking giant routinely rejects ads from Yarrow, which sells pants specially fitted for people in wheelchairs. Facebook doesn’t allow ads for medical equipment, and apparently the algorithm concluded that the ads were for wheelchairs. Yarrow has successfully appealed the rejections, which takes an average of 10 days each.
- Patty + Ricky, a marketplace that sells clothing for people with disabilities, has appealed Facebook’s rejection of 200 adaptive fashion products.
Behind the news: Other social media platforms have been tripped up by well-intentioned efforts to control harmful speech.
- YouTube blocked a popular chess channel for promoting harmful and dangerous content. Apparently, its algorithm objected to words like “black,” “white,” “attack,” and “threat” in descriptions of chess matches.
- In 2019, TikTok admitted to suppressing videos made by users who were disabled, queer, or overweight, purportedly an effort to discourage bullying.
Why it matters: Millions of small businesses advertise on Facebook and Instagram, many of which serve niche communities. For such companies, being barred from promoting their wares on these platforms is a major blow.
We’re thinking: Moderating content on platforms as big as Facebook would be impossible without AI. But these cases illustrate how far automated systems are from being able to handle the job by themselves. Humans in the loop are still required to mediate between online platforms and their users.
A MESSAGE FROM DEEPLEARNING.AI
.png?upscale=true&name=The%20Batch%20Image%20(2).png)
Last day to register for “Optimizing BizOps with AI,” an Expert Panel presented in collaboration with FourthBrain. Technical leaders at Amazon, Samsung, and Uber will explain how they’re deploying AI to improve business efficiency. Join us on Feb. 25, 2021, at 4 p.m. Pacific Standard Time! RSVP

Cake + Cookie = Cakie
AI may help revolutionize the human diet – or dessert, at least.
What’s new: Google applied AI engineer Dale Markowitz and developer advocate Sara Robinson trained a model to predict whether a recipe is a bread, cake, or cookie. They brightened the recent holiday season by using it to develop novel hybrid recipes.
How it works: The engineers conceived their project to demonstrate Google’s AutoML, a software suite for easy-bake machine learning.
- They compiled and labeled roughly 600 recipes for breads, cakes, or cookies and limited ingredient lists to 16 essentials, like eggs, flour, and milk.
- They trained a model to classify recipes as bread, cake, or cookies with high accuracy.
- For each recipe, AutoML’s explainability feature assigned the ingredients a percentage that described their importance to the classification. Butter, sugar, and yeast were most important overall.
- The authors adjusted ingredient ratios until they developed a recipe that the model classified as equal parts cookie and cake, and another that was equal parts bread and cookie. They baked and tasted these creations: a cakie (“nasty”) and a breakie (“pretty good”).
Behind the news: Machine learning’s culinary education is coming along, though some of its creations are tastier than others.
- Sony AI’s Flagship Gastronomy Project recently launched an app to help professional chefs develop new recipes, food pairings, and menus.
- In 2019, Facebook trained a vision model to recognize different types of food and generate recipes to produce them.
- In 2016, IBM debuted Chef Watson, an app trained partly on Bon Appétit’s recipe archive, which generates recipes based on ingredients specified by users.
- Blogger Janelle Shane prompted GPT-2 to generate recipes for dish names that were themselves generated by AI, producing gustatory horrors like Chocolate Chicken Chicken Cake.
Why it matters: Experimenting with new recipes isn’t just fun for home cooks. Commercial test kitchens are on the lookout for novel flavors, textures, and dishes. AI could help chefs invent smorgasbords of culinary delights.
We’re thinking: These AI-powered recipes may seem half-baked, but suddenly we have a craving for Chocolate Chicken Chicken Cake.
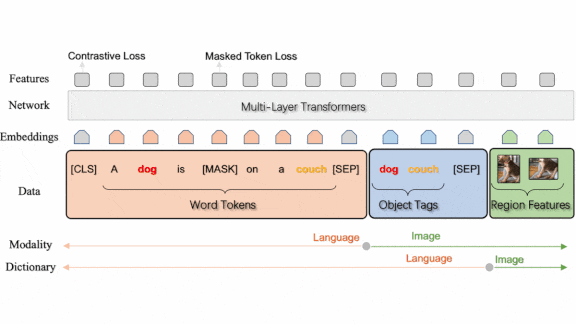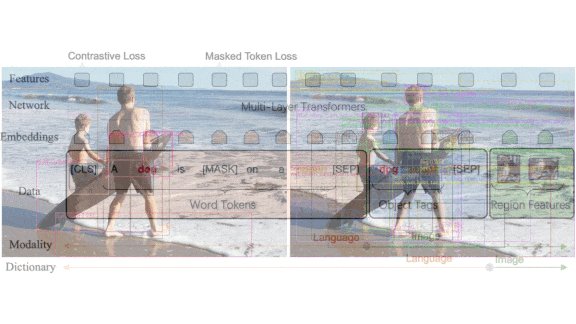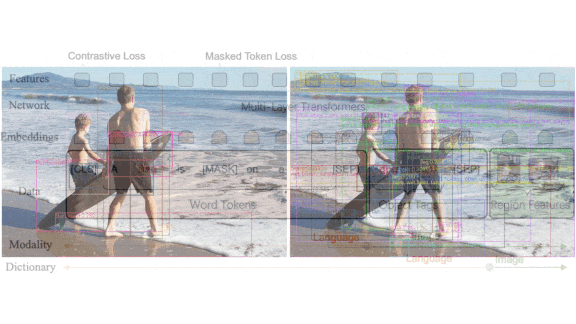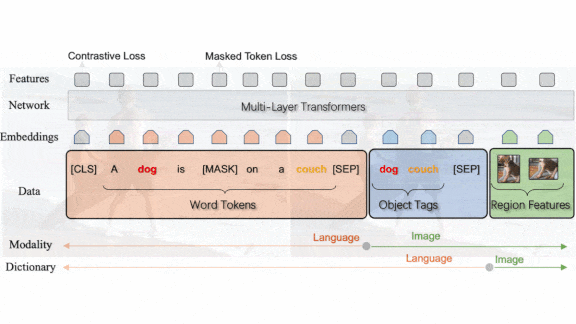
Sharper Eyes For Vision+Language
Models that interpret the interplay of words and images tend to be trained on richer bodies of text than images. Recent research worked toward giving such models a more balanced knowledge of the two domains.
What’s new: Pengchuan Zhang and Xiujun Li led a team at Microsoft and University of Washington raised the bar in several vision-and-language tasks. They call their system Oscar+, building on earlier work that used class names of objects in an image to improve matching of image and text representations.
Key insight: Recent progress in vision-and-language models has come mostly by combining learned image and text representations more effectively rather than improving the representations themselves, the authors observed. Honing these representations through additional pretraining ought to boost their performance.
How it works: The authors started with pretrained representations for images and text generated by separate models for vision (ResNeXt-152 C4 pretrained on ImageNet-5k) and language (pretrained BERT). They honed the image representations by further pretraining the vision model on new data. Then they generated image-and-text representations as they pretrained Oscar+ as a whole. Finally, they fine-tuned the system on specific vision-and-language tasks.
- In the additional pretraining step, the authors pretrained the ResNeXt-152 C4 to detect 1,848 objects or attributes (such as labels describing colors or textures) in 2.49 million images in four object detection datasets.
- A transformer fused image and text representations as the authors pretrained Oscar+ on 8.85 million examples from four image caption datasets with generated image tags, image tag datasets with generated captions, and visual question-and-answer datasets. At this stage, the system optimized two loss terms. One term encouraged the system to predict randomly hidden words in a caption or an image’s tags. The other term encouraged the system to match an image and its tags, or an answer with its question and its image.
- They fine-tuned the system to perform seven specific tasks.
Results: Oscar+ achieved state-of-the-art results in all seven tasks, from matching images with captions (and vice-versa) to determining the truth of a statement about two images. The system boosted NoCaps accuracy (captioning images that contain objects not seen in training) to 92.5 percent from 86.6 percent — its biggest gain. To show that performance was substantially improved by separately pretraining the object detector on additional data, the authors compared performance with and without that step. That step boosted visual question-answering accuracy, for instance, to 74.90 percent from 71.34 percent.
Why it matters: Performance in multimodal tasks can improve with additional learning in just one of the modes involved.
We’re thinking: If Oscar is a grouch, is Oscar+ nicer — or even more grumpy?
Work With Andrew Ng
Enterprise Customer Success Manager: Workera seeks an enterprise customer success manager to manage our growing customer base and help build out our go-to-market teams. Apply here
DevOps Engineer (Remote Contractor): Workera is looking for a DevOps engineer who can work on a part-time or project basis to help us build secure, high-performing, resilient, and efficient infrastructure for our growing application and workloads. Apply here
Investment Associate: AI Fund seeks an energetic Associate to join our investment team and help us identify the best early-stage companies leveraging AI today and help our portfolio companies grow. We welcome candidates who possess a growth mindset, strong analytical skills, and the ability to handle ambiguity. Apply here
Senior Software Development Engineer (North America, Latin America, China): Landing AI seeks software engineers experienced in backend infrastructure, network security, and cloud or edge device development. In this role, you will be responsible for developing scalable AI applications and delivering optimized inference software for our clients in manufacturing, agriculture, and healthcare. Check out our positions in North America, Latin America and China.
Full-Stack Engineer: At AI Fund, we are looking for full-stack engineers to produce scalable software solutions for our portfolio companies. You’ll be part of a cross-functional team and will be responsible for software development from conception to deployment. Apply here
Machine Learning Instructor: FourthBrain.AI is looking for an instructor to join its early-stage AI training startup. The instructor will work closely with the curriculum development director to manage students in a part-time ML training program. Apply here
Senior Software Engineer — Front End: Workera seeks software engineers experienced in front-end development. In this role, you will build the world’s leading assessment technology to help members of the AI community evaluate their skills and know where they stand. Apply here
Enterprise Sales Development Representative: Workera seeks an enterprise sales rep to drive new business opportunities by qualifying and nurturing leads for the global enterprise sales team in support of our rapidly growing business. Apply here
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
Copyright 2021 DeepLearning.AI, 195 Page Mill Road, Suite 115, Palo Alto, CA 94306, United States. All rights reserved.
|
