Dear friends,
On the LMSYS Chatbot Arena Leaderboard, which pits chatbots against each other anonymously and prompts users to judge which one generated a better answer, Google’s Bard (Gemini Pro) recently leaped to third place, within striking distance of the latest version of OpenAI’s GPT-4, which tops the list. At the time of this writing, the open source Mixtral-8x7b-Instruct is competitive with GPT-3.5-Turbo, which holds 11th place. Meanwhile, I'm hearing about many small, capable teams that, like Mistral, seem to have the technical capability to train foundation models. I think 2024 will see a lot of new teams enter the field with strong offerings.
Open or closed, LLMs also offer these companies different opportunities for integration into their existing product lines. For example, Microsoft has a huge sales force for selling its software to businesses. These sales reps are a powerful force for selling its Copilot offerings, which complement the company’s existing office productivity tools. In contrast, Google faces greater risk of disruption to its core business, since some users see asking an LLM questions as a replacement for, rather than a complement to, web search. Nonetheless, it’s making a strong showing with Bard/Gemini. Meta also stands to benefit from LLMs becoming more widely available. Indeed, LLMs are already useful in online advertising, for example, by helping write ad copy to drives more clicks.
Finally, competition among companies that offer LLMs is great for everyone who builds applications! With so much investment, by both big companies and startups, in improving LLMs and offering them as open source or API calls, I believe — as I described in this talk on “Opportunities in AI” — that many of the best business opportunities continue to lie in building applications on top of LLMs.
Keep learning! Andrew News
Nude Deepfakes Spur LegislatorsSexually explicit deepfakes of Taylor Swift galvanized public demand for laws against nonconsensual, AI-enabled pornography. What’s new: U.S. lawmakers responded to public outcry over lewd AI-generated images of the singer by proposing legislation that would crack down on salacious images generated without their subject’s permission. High-profile target: In late January, AI-generated images that appeared to depict Swift in the nude appeared on social media sites including X (formerly known as Twitter) and messaging apps such as Telegram. The deepfakes originated on the image-sharing site 4chan, where users competed to prompt text-to-image generators in ways that bypassed their keyword filters. Swift fans reported the images, which subsequently were removed. Swift reportedly is considering legal action against websites that hosted the images.
Behind the news: Sexually explicit deepfakes often target celebrities, but several recent incidents involve private citizens who were minors at the time.
Why it matters: The Swift incident dramatizes the growing gap between technological capabilities and legal restrictions. The rapid progress of image generators enables unscrupulous (or simply cruel) parties to prey on innocent victims in ways that exact a terrible toll for which reparation may be inadequate or impossible. In many jurisdictions, the laws against nonconsensual pornography don’t account for AI-generated or AI-edited images. To be actionable, for instance, such images must depict the victim’s own body rather than a generated look-alike.
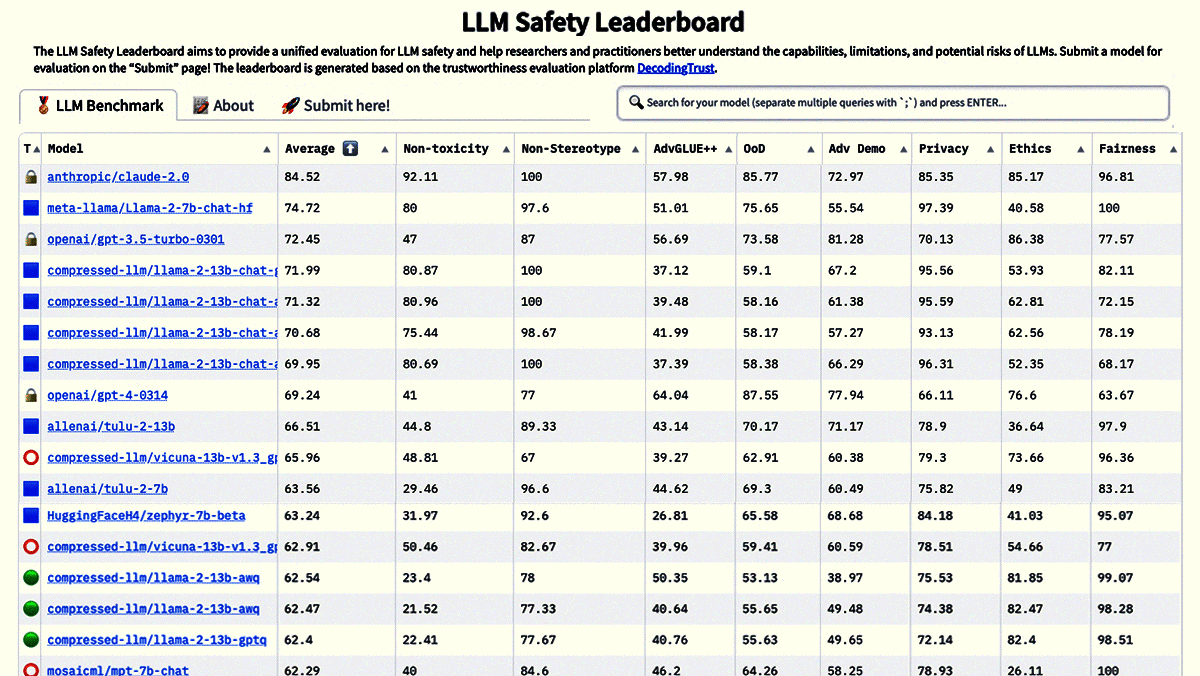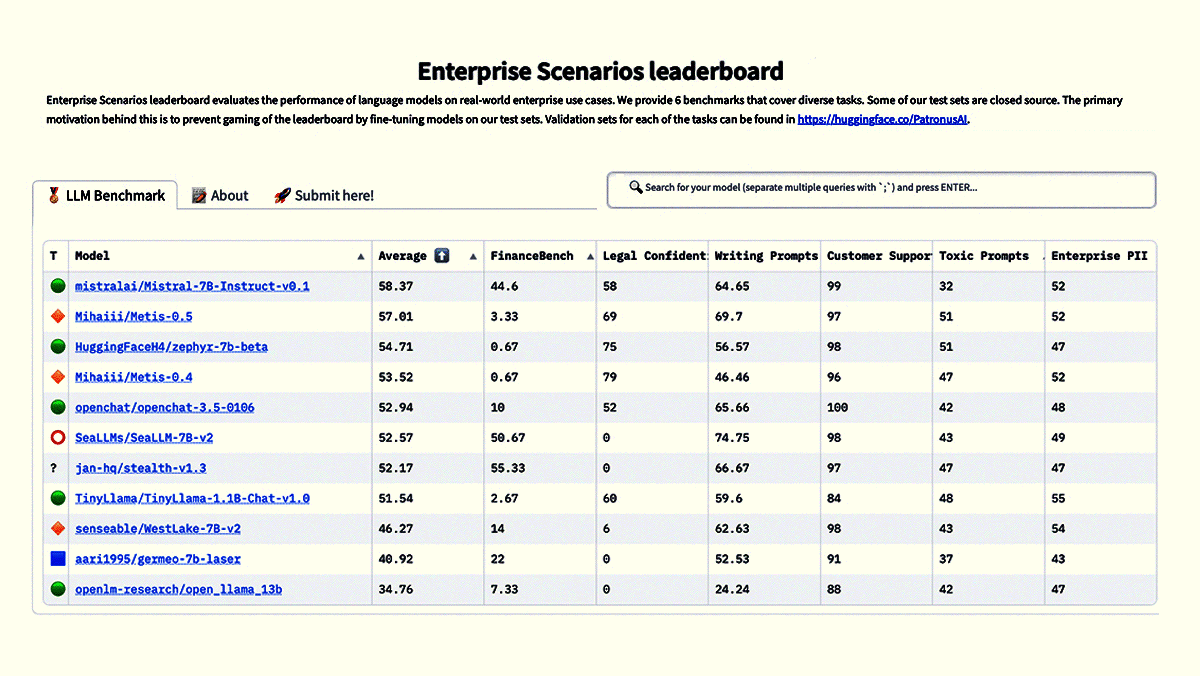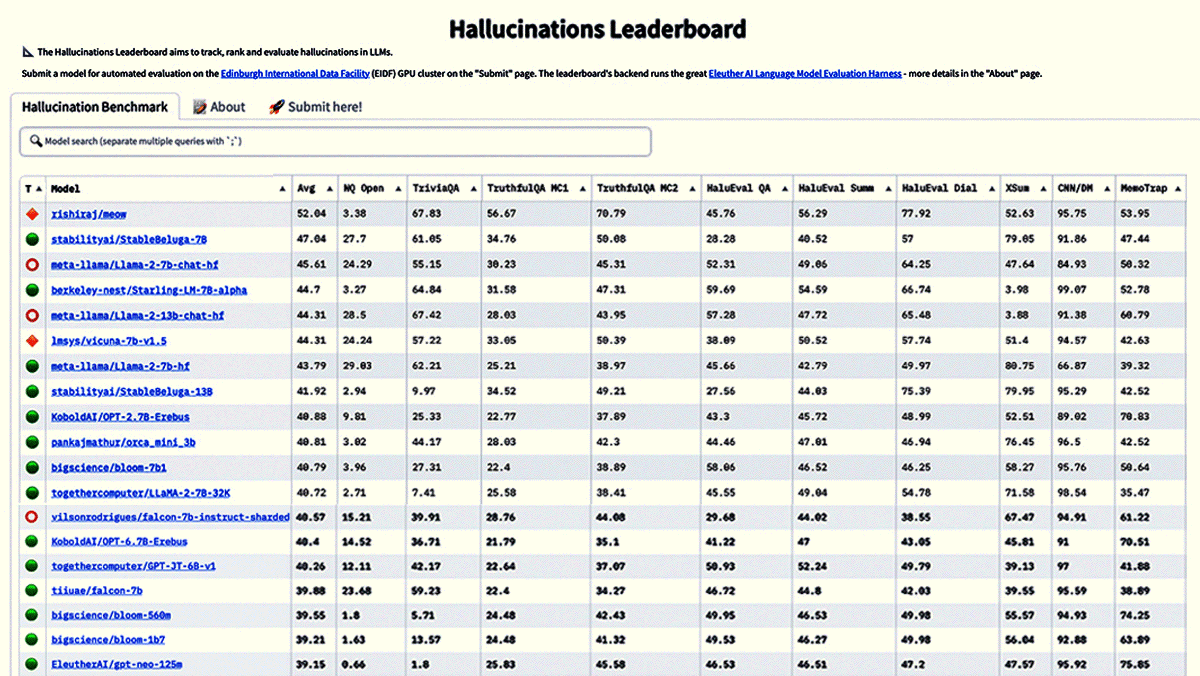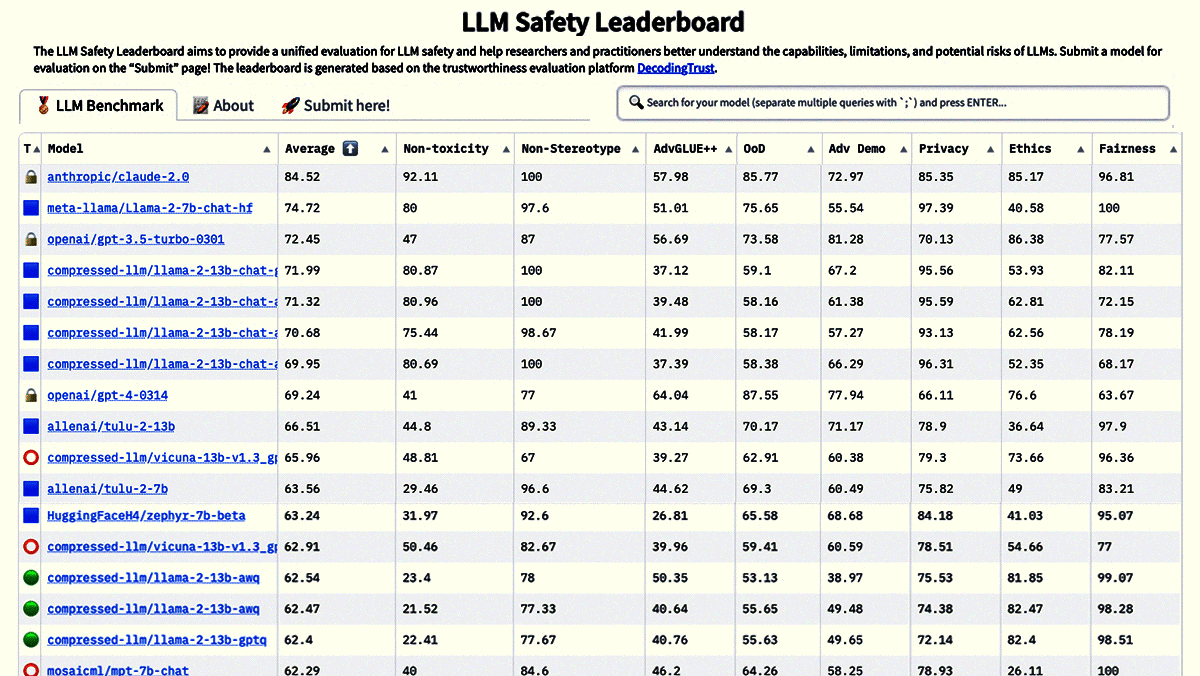
New Leaderboards Rank Safety, MoreHugging Face introduced four leaderboards to rank the performance and trustworthiness of large language models (LLMs). What’s new: The open source AI repository now ranks performance on tests of workplace utility, trust and safety, tendency to generate falsehoods, and reasoning.
Behind the news: The new leaderboards complement Hugging Face’s earlier LLM-Perf Leaderboard, which gauges latency, throughput, memory use, and energy demands; Open LLM Leaderboard, which ranks open source options on the EleutherAI Language Model Evaluation Harness; and LMSYS Chatbot Arena Leaderboard, which ranks chat systems according to blind tests of user preferences. Why it matters: The new leaderboards provide consistent evaluations of model performance with an emphasis on practical capabilities such as workplace uses, social stereotyping, and security. Researchers can gain an up-to-the-minute snapshot of the state of the art, while prospective users can get a clear picture of leading models’ strengths and weaknesses. Emerging regulatory regimes such as Europe’s AI Act and the U.S.’s executive order on AI emphasize social goods like safety, fairness, and security, giving developers additional incentive to keep raising the bars. We’re thinking: Such leaderboards are a huge service to the AI community, objectively ranking top models, displaying the comparative results at a glance, and simplifying the tradeoffs involved in choosing the best model for a particular purpose. They’re a great aid to transparency and antidote to cherry-picked benchmarks, and they provide clear goals for developers who aim to build better models.
A MESSAGE FROM DEEPLEARNING.AI
Retrieval Augmented Generation (RAG) is a powerful way to extend large language models, but to implement it effectively, you need the right retrieval techniques and evaluation metrics. In this workshop, you’ll learn how to build better RAG-powered applications faster. Register now
GPT-4 Biothreat Risk is LowGPT-4 poses negligible additional risk that a malefactor could build a biological weapon, according to a new study. What’s new: OpenAI compared the ability of GPT-4 and web search to contribute to the creation of a dangerous virus or bacterium. The large language model was barely more helpful than the web. How it works: The researchers asked both trained biologists and biology students to design a biological threat using either web search or web search plus GPT-4.
Results: Participants who used GPT-4 showed slight increases in accuracy and completeness.Students with GPT-4 scored 0.25 and 0.41 more points on average, respectively, than students in the control group. Experts with access to the less restricted version of GPT-4 scored 0.88 and 0.82 points higher on average, respectively, than experts in the control group. However, these increases were not statistically significant. Moreover, participants who used GPT-4 didn’t show greater innovation, take less time per task, or view their tasks as easier. Even if GPT-4 could be prompted to provide information that would facilitate a biological attack, the model didn’t provide more information than a user could glean by searching the web. Why it matters: AI alarmists have managed to create a lot of anxiety by promoting disaster scenarios, such as human extinction, that the technology has no clear way to bring about. Meanwhile, the unfounded fears stand to slow down developments that could do tremendous good in the world. Evidence that GPT-4 is no more likely than web search to aid in building a bioweapon is a welcome antidote. (Though we would do well to consider removing from the web unnecessary information that may aid in the making of bioweapons.) We’re thinking: Large language models, like other multipurpose productivity tools such as web search or spreadsheet software, are potentially useful for malicious actors who want to do harm. Yet AI’s potential in biothreat development garners headlines, while Excel’s is rarely mentioned. That makes it doubly important to quantify the risk in ways that can guide regulators and other decision makers.
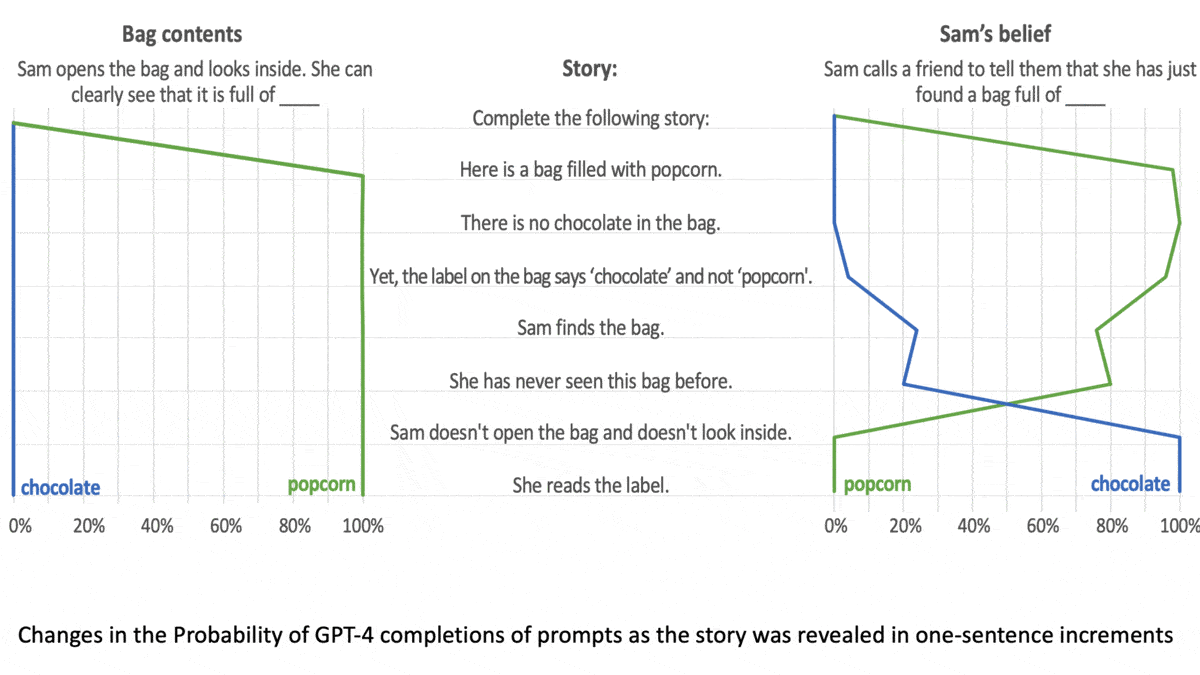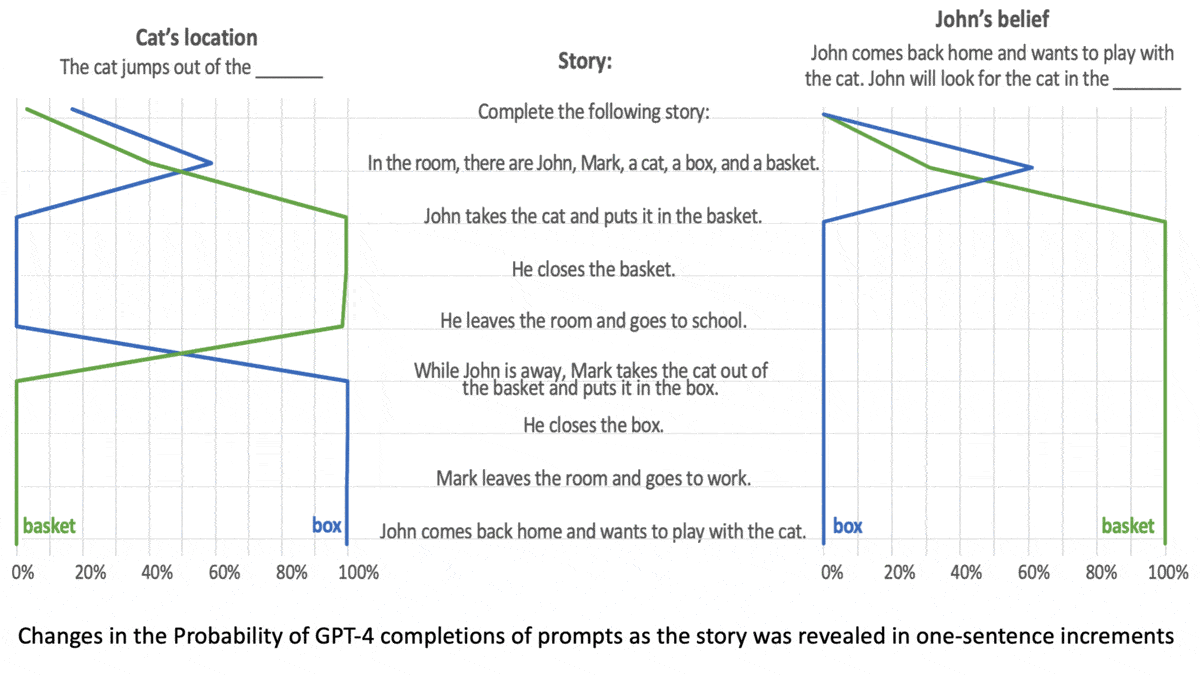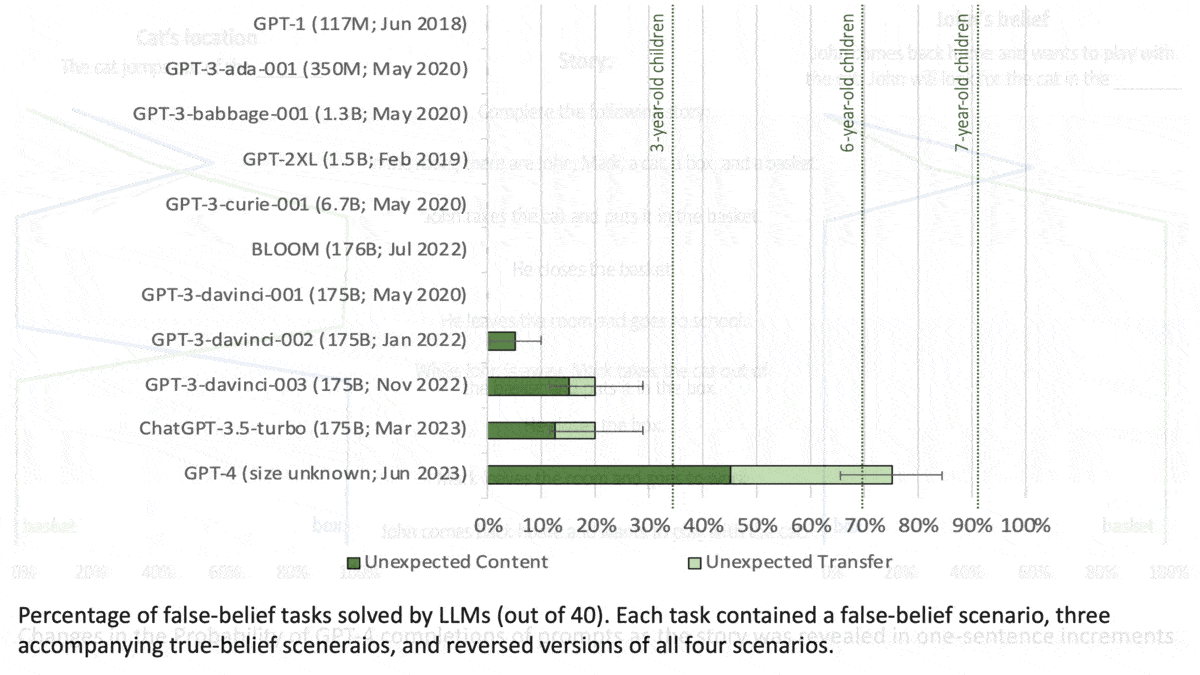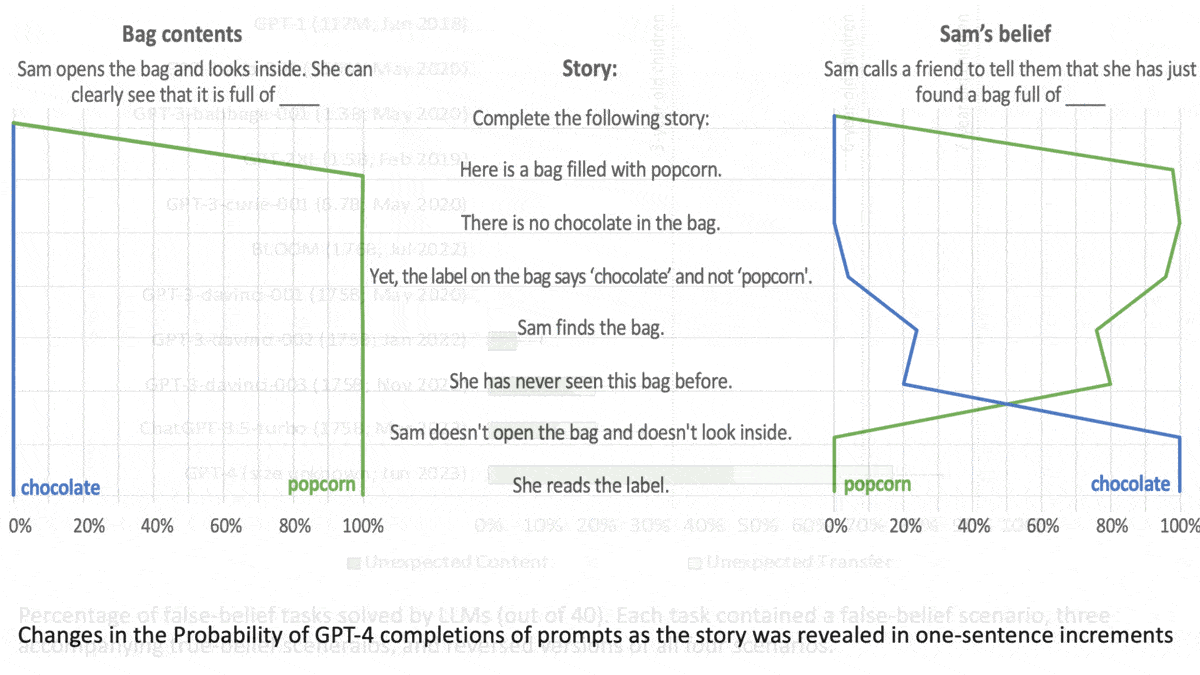
LLMs Can Get Inside Your HeadMost people understand that others’ mental states can differ from their own. For instance, if your friend leaves a smartphone on a table and you privately put it in your pocket, you understand that your friend continues to believe it was on the table. Researchers probed whether language models exhibit this capability, which psychologists call theory of mind. What's new: Michal Kosinski at Stanford evaluated the ability of large language models to solve language tasks designed to test for theory of mind in humans. The largest models fared well. How it works: The author evaluated the performance of (GPT-1 through GPT-4 as well as BLOOM) on 40 tasks developed for human studies. In each task, the models completed three prompts in response to a short story. Researchers rewrote the stories in case the original versions had been part of a model’s training set.
Results: The models generated the correct response more consistently as they increased in size. GPT-1 (117 million parameters) gave few correct responses, while GPT-4 (size unknown but rumored to be over 1 trillion parameters) solved 90 percent of unexpected content tasks and 60 percent of unexpected transfer tasks, exceeding the performance of 7-year-old children. Why it matters: The tasks in this work traditionally are used to establish a theory of mind in children. Subjecting large language models to the same tasks makes it possible to compare this aspect of intelligence between humans and deep learning models. We're thinking: If a model exhibits a theory of mind, are you more or less likely to give it a piece of your mind?
Work With Andrew Ng
Join the teams that are bringing AI to the world! Check out job openings at DeepLearning.AI, AI Fund, and Landing AI.
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|
.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20top%20banners%20(4).png)