Dear friends,
I’ve always believed in democratizing access to the latest advances in artificial intelligence. As a step in this direction, we just launched “Generative AI for Everyone” on Coursera. The course assumes no programming or AI background, and I hope it will be useful to students, teachers, artists, scientists, engineers, leaders in business and government, and anyone else who simply wants to know how to apply generative AI in their work or personal life. Please check it out and encourage your friends to take a look, especially those with a nontechnical background.
If you’re an engineer: I designed this course to be accessible to nontechnical professionals partly to help technical people work with them more easily. With earlier waves of technology, I found that the gap in understanding between technical and nontechnical people got in the way of putting the technology to use. So if you already have a good understanding of generative AI, please encourage your nontechnical colleagues to take this course. They will learn a lot, and I hope this will help you collaborate more productively!
Keep learning! Andrew
News
White House Moves to Regulate AIU.S. President Biden announced directives that control AI based on his legal power to promote national defense and respond to national emergencies. What’s new: The White House issued an executive order that requires AI companies and institutions to report and test certain models and directs federal agencies to set standards for AI. The order follows a six-month process of consultation with the AI community and other stakeholders. How it works: The executive order interprets existing law — specifically the Cold War-era Defense Production Act, a Cold War-era law that gives the president powers to promote national defense and respond to emergencies — and thus can be implemented without further legislation. It focuses on foundation models, or general-purpose models that can be fine-tuned for specific tasks:
Behind the news: The executive order was long in the making and joins other nations’ moves to limit AI.
Why it matters: While Europe and China move aggressively to control specific uses and models, the White House seeks to balance innovation against risk, specifically with regard to national defense but also social issues like discrimination and privacy. The executive order organizes the federal bureaucracy to grapple with the challenges of AI and prepares the way for national legislation. We’re thinking: We need laws to ensure that AI is safe, fair, and transparent, and the executive order has much good in it. But it’s also problematic in fundamental ways. For instance, foundation models are the wrong focus. Burdening basic technology development with reporting and standards places a drag on innovation. It makes more sense to regulate applications that carry known risks, such as underwriting tools, healthcare devices, and autonomous vehicles. We welcome regulations that promote responsible AI and look forward to legislation that limits risks without hampering innovation.
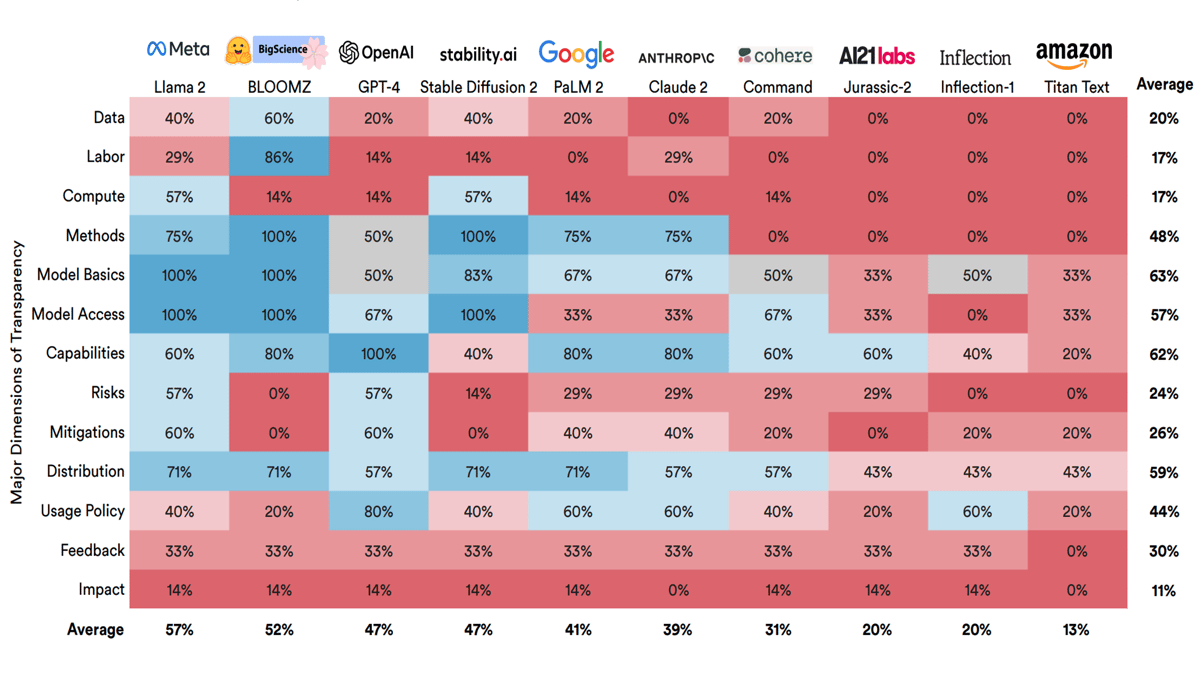
What We Know — and Don’t Know — About Foundation ModelsA new index ranks popular AI models in terms of information their developers provide about their training, architecture, and usage. Few score well. What’s new: The Stanford Center for Research on Foundation Models published its debut Foundation Model Transparency Index, scoring 10 popular models on how well their makers disclosed details of their training, characteristics, and use. How it works: Rishi Bommasani, Kevin Klyman, and colleagues at Stanford, MIT, and Princeton examined 10 foundation models — that is, models that can be pretrained for general purposes and fine-tuned for specific tasks — from 10 companies. They scored each model by asking 100 yes-or-no questions that covered training, model architecture and behavior, and policies regarding access and usage.
Results: The index assigned each model a score between 1 and 100. Meta’s Llama 2 ranked most transparent with a score of 54. BigScience’s BLOOM-Z came in just behind with a score of 53. At the bottom of the list were Inflection’s Inflection-1, which scored 21, and Amazon’s Titan Text, which scored 12.
Yes, but: Because the index is limited to yes/no questions, it doesn’t allow for partial credit. In addition, the questions are weighted equally, so lack of transparency in an important area (say, access to training data) costs only one point in a model’s overall score. It’s easy to imagine companies gaming the scores rather than addressing the most meaningful deficits. Behind the news: Researchers at MIT, Cohere For AI, and 11 other organizations recently launched the Data Provenance Platform, a project that audits and categorizes training datasets. The effort offers a Data Provenance Explorer for evaluating sources, licenses, creators, and other metadata with respect to roughly 1,800 text datasets. Why it matters: AI has a transparency problem, and the rise of models that serve as foundations for other models exacerbates the issue. Without disclosure of fundamental factors like architectures, datasets, and training methods, it’s impossible to replicate research, evaluate cost per performance, and address biases. Without disclosure of applications based on a given foundation model, it’s impossible to weigh those applications’ capabilities and limitations. A consistent set of criteria for evaluating transparency may encourage greater disclosure.
A MESSAGE FROM DEEPLEARNING.AI
Andrew Ng’s new course, “Generative AI for Everyone,” is live on Coursera! Learn how to use generative AI in your life and work, what this technology can (and can’t) do, and how to put it to use in the real world. Enroll today to get started!
Cruise ControlThe state of California pulled the parking brake on Cruise driverless vehicles. What’s new: The California Department of Motor Vehicles (DMV) suspended Cruise’s permit to operate vehicles in the state without safety drivers. The General Motors subsidiary responded by halting its robotaxi operations across the United States. How it works: The California DMV acted following an early October incident in San Francisco. A Cruise driverless car struck and trapped a pedestrian who had been thrown into its path by a separate hit-and-run.
Behind the news: Cruise’s deployment of driverless taxis in San Francisco has been troubled.
Why it matters: Cruise’s latest trouble is a serious setback not just for GM, but for the self-driving car industry, which has been criticized for overpromising and underdelivering. The California DMV’s act has energized politicians, activists, and other public figures who oppose driverless taxis. We’re thinking: The AI community must lean into transparency to inspire the public’s trust. California determined that Cruise was not fully forthcoming about its role in the incident — a serious breach of that trust. Voluntary suspension of operations is a welcome step toward restoring it. We hope the company takes the opportunity to conduct a comprehensive review.
Synthetic Data Helps Image GeneratorsText-to-image generators often miss details in text prompts, and sometimes they misunderstand parts of a prompt entirely. Synthetic captions can help them follow prompts more closely. What’s new: James Betker, Gabriel Goh, Li Jing, and Aditya Ramesh at OpenAI, along with colleagues at Microsoft, improved a latent diffusion model’s performance by training it on an image-caption dataset including model-generated captions that were more detailed than those typically scraped from the web. They used the same technique to train DALL·E 3, the latest version of OpenAI’s text-to-image generator. Key insight: Text-to image generators learn about the relationships between images and their descriptions from datasets of paired images and captions. The captions in typical image-caption datasets are limited to general descriptions of image subjects, with few details about the subjects and little information about their surroundings, image style, and so on. This makes models trained on them relatively insensitive to elaborate prompts. However, language models can generate captions in great detail. Training on more-detailed synthetic captions can give an image generator a richer knowledge of the correspondence between words and pictures. How it works: Rather than reveal details about DALL·E 3’s architecture and training, the authors describe training a latent diffusion model.
Results: The authors trained separate latent diffusion models on datasets containing 95 percent generated captions and 100 percent human-made captions. They used the models to generate 50,000 images each and used OpenAI’s CLIP to calculate a similarity score (higher is better) between the prompts and generated images. The model trained on synthetic captions achieved 27.1 CLIP similarity, while a model trained on human-made captions achieved 26.8 CLIP similarity. Testing DALL·E 3: The authors also tested human responses to images generated by DALL·E 3, Midjourney 5.2, and Stable Diffusion XL v1.0. Shown images based on 170 prompts selected by the authors, human judges found DALL·E 3’s output more true to the prompt and more appealing. Shown images based on 250 captions chosen at random from MSCOCO, they found DALL·E 3’s output most realistic. In a similar test, DALL·E 3 achieved a higher score on the Drawbench dataset than Stable Diffusion XL v1.0 and DALL-E 2. (No word on how DALL·E 3 compared to Midjourney in this experiment.) Why it matters: Synthetic data is used increasingly to train machine learning models. The market research firm Gartner says that output from generative models will constitute 60 percent of data used in AI development by 2024. While synthetic data has been shown to boost performance in typical training methods, recursively training one model on another model’s output can distort the trained model’s output distribution — a scenario that could manifest over time as more models trained on synthetic data are used to generate data to train subsequent models. We’re thinking: Using one AI model to help another to learn seems to be an emerging design pattern. For example, reinforcement learning from AI feedback (RLAIF) uses AI to rate output from large language models, rather than reinforcement learning from human feedback (RLHF). It’s a fair bet that we’ll see many more techniques along this line.
A MESSAGE FROM LANDING AI
Learn how to identify and scope vision applications, choose a project type and model, apply data-centric AI, and develop an MLOps pipeline in “Building Computer Vision Applications” with Andrew Ng. Join us on Monday, November 6, 2023, at 10 a.m. Pacific Time. Register here
Work With Andrew Ng
Join the teams that are bringing AI to the world! Check out job openings at DeepLearning.AI, AI Fund, and Landing AI.
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|
.png?upscale=true&width=1200&upscale=true&name=January%2025%2c%202023%20(30).png)


.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20ads%20and%20exclusive%20banners%20(72).png)


.png?upscale=true&width=1200&upscale=true&name=unnamed%20(68).png)