Dear friends,
My team at Landing AI just announced a new tool for quickly building computer vision models, using a technique we call Visual Prompting. It’s a lot of fun! I invite you to try it.
To build a text sentiment classifier, in the traditional machine learning workflow, you have to collect and label a training set, train a model, and deploy it before you start getting predictions. This process can take days or weeks.
In contrast, in the prompt-based machine learning workflow, you can write a text prompt and, by calling a large language model API, start making predictions in seconds or minutes.
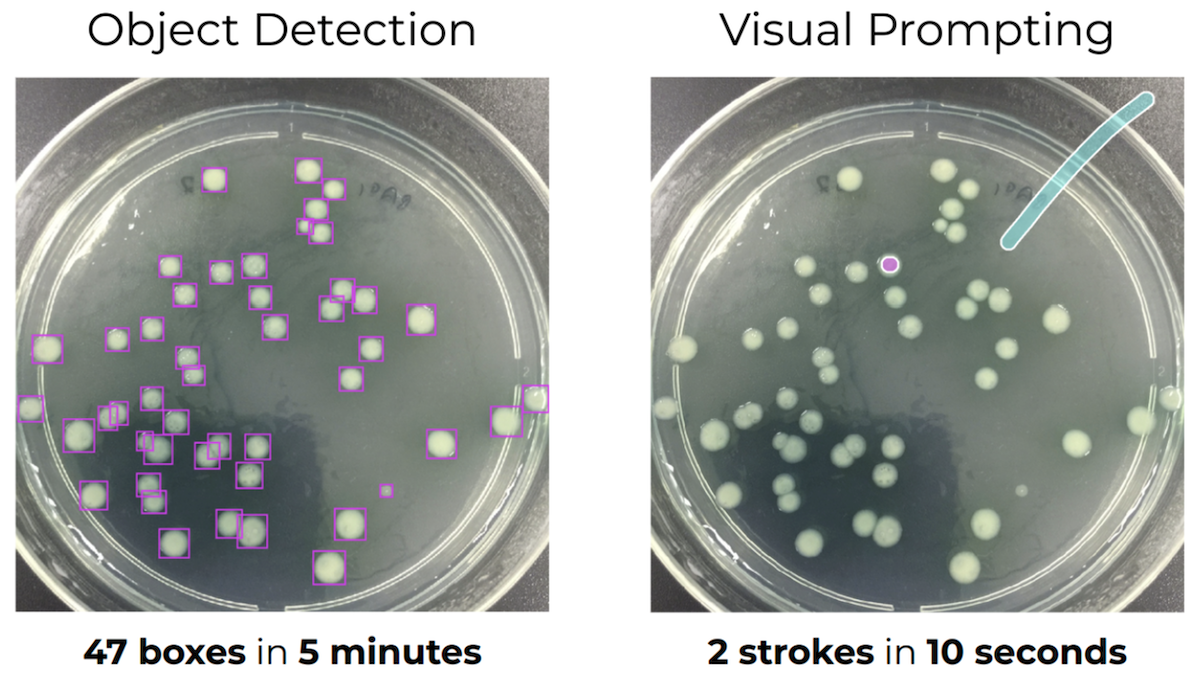
To explain how these ideas apply to computer vision, consider the task of recognizing cell colonies (which look like white blobs) in a petri dish, as shown in the image below. In the traditional machine learning workflow, using object detection, you would have to label all the cell colonies, train a model, and deploy it. This works, but it’s slow and tedious.
The resulting interaction feels like you’re having a conversation with the system. You’re guiding it by incrementally providing additional data in real time.
Keep learning! Andrew
News
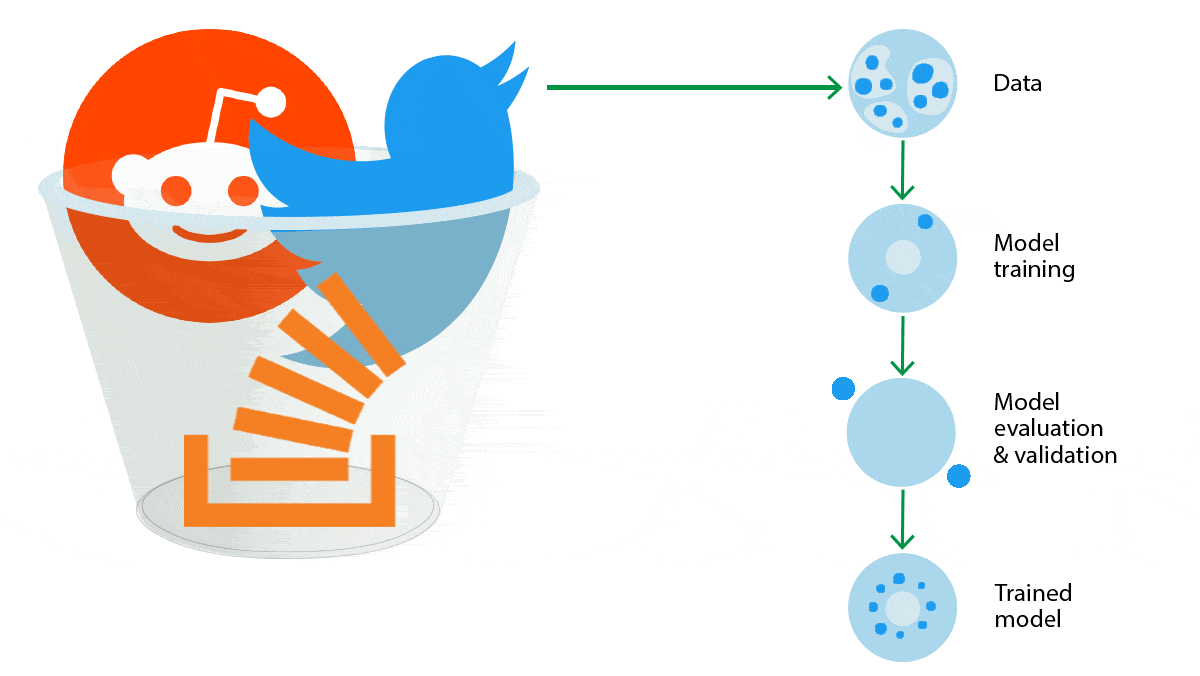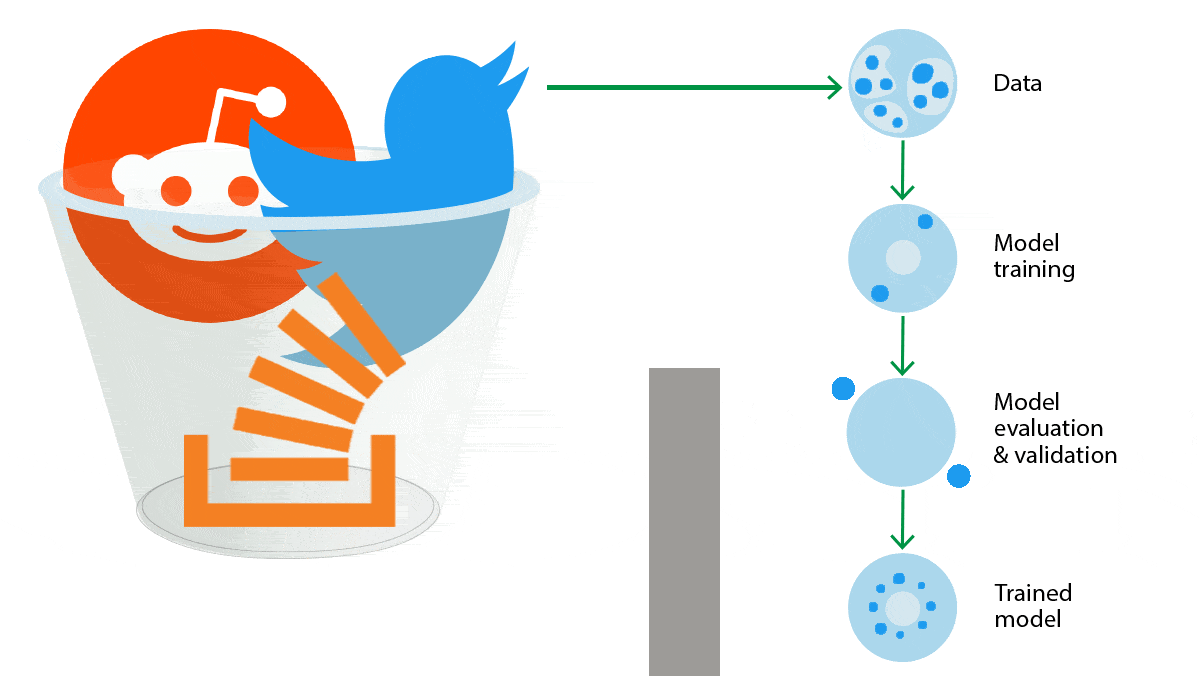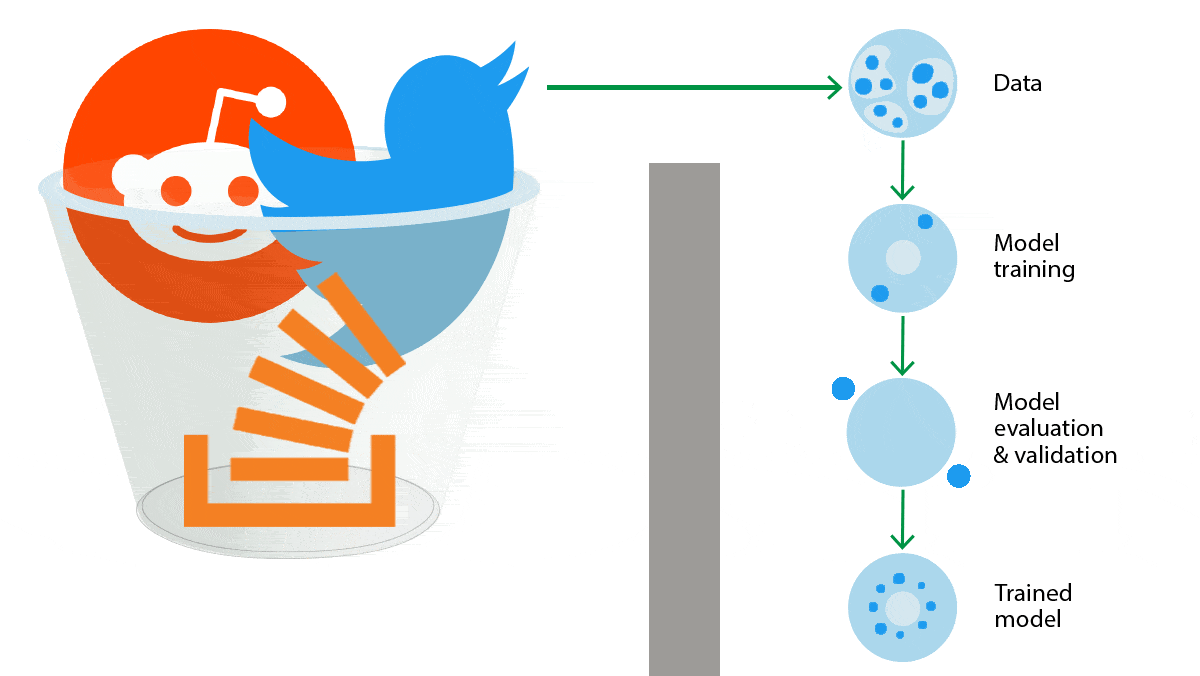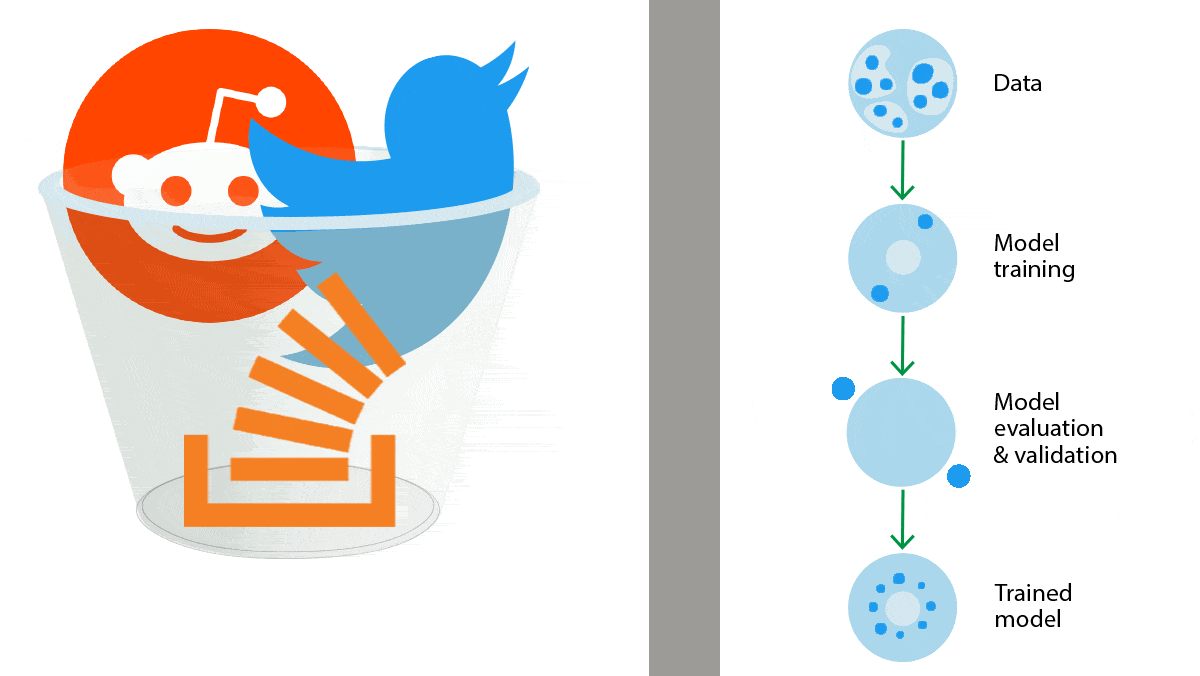
Data Does Not Want to Be FreeDevelopers of language models will have to pay for access to troves of text data that they previously got for free. What’s new: The discussion platform Reddit and question-and-answer site Stack Overflow announced plans to protect their data from being used to train large language models. How it works: Both sites offer APIs that enable developers to scrape data, like posts and conversations, en masse. Soon they'll charge for access.
What they’re saying: “Community platforms that fuel LLMs absolutely should be compensated for their contributions so that companies like us can reinvest back into our communities to continue to make them thrive,” Chandrasekar told Wired. Behind the news: In February, Twitter started charging up to $42,000 monthly for use of its API. That and subsequent API closures are part of a gathering backlash against the AI community’s longstanding practice of training models on data scraped from the web. This use is at issue in ongoing lawsuits. Last week a collective of major news publishers stated that training AI on text licensed from them violates their intellectual property rights. Why it matters: Although data has always come at a cost, the price of some corpora is on the rise. Discussion sites like Reddit are important repositories of conversation, and text from Stack Overflow has been instrumental in helping to train language models to write computer code. The legal status of existing datasets and models is undetermined, and future access to data depends on legal and commercial agreements that have yet to be negotiated.
Conversational Search, Google StyleGoogle’s response to Microsoft’s GPT-4-enhanced Bing became a little clearer. What’s new: Anonymous insiders leaked details of Project Magi, the search giant’s near-term effort to enhance its search engine with automated conversation, The New York Times reported. They described upcoming features, but not the models behind them. How it works: Nearly 160 engineers are working on the project.
Beyond search: The company is developing AI-powered features for other parts of its business as well. These include an image generation tool called GIFI for Google Images and a chatbot called Tivoli Tutor for learning languages. Why it matters: When it comes to finding information, conversational AI is a powerful addition to, and possibly a replacement for, web search. Google, as the market leader, can’t wait to find out. The ideas Google and its competitors implement in coming months will set the mold for conversational user interfaces in search and beyond.
A MESSAGE FROM DEEPLEARNING.AI
Are you ready to turn your passion into practice? The new AI for Good Specialization will empower you to use machine learning and data science for positive social and environmental impact! Join the waitlist to be the first to enroll
Everybody Must Get ClonedTech-savvy music fans who are hungry for new recordings aren’t waiting for their favorite artists to make them. What’s new: Social media networks exploded last week with AI-driven facsimiles of chart-topping musicians. A hiphop song with AI-generated vocals in the styles of Drake and The Weeknd racked up tens of millions of listens before it was taken down. Soundalikes of Britpop stars Oasis, rapper Eminem, and Sixties stalwarts The Beach Boys also captured attention. How it works: These productions feature songs composed and performed in the old-fashioned way overlaid with celebrity-soundalike vocals generated by voice-cloning models. Some musicians revealed their methods.
Behind the news: The trend toward AI emulations of established artists has been building for some time. In 2021, Lost Tapes of the 27 Club used an unspecified AI method to produce music in the style of artists who died young including Jimi Hendrix, Kurt Cobain, and Amy Winehouse. The previous year, OpenAI demonstrated Jukebox, a system that generated recordings in the style of many popular artists. Yes, but: The record industry is moving to defend its business against such audio fakery (or tributes, depending on how you want to view them). Universal Music Group, which controls about a third of the global music market, recently pushed streaming services to block AI developers from scraping musical data or posting songs in the styles of established artists. Why it matters: Every new generation of technology brings new tools to challenge the record industry’s control over music distribution. The 1970s brought audio cassettes and the ability to cheaply copy music, the 1980s brought sampling, the 1990s and 2000s brought remixes and mashups. Today AI is posing new challenges. Not everyone in the music industry is against these AI copycats: The electronic artist Grimes said she would share royalties with anyone who emulates her voice, and Oasis’ former lead singer apparently enjoyed the AI-powered imitation.
Image Generators Copy Training DataWe know that image generators create wonderful original works, but do they sometimes replicate their training data? Recent work found that replication does occur. What's new: Gowthami Somepalli and colleagues at University of Maryland devised a method that spots instances of image generators copying from their training sets, from entire images to isolated objects, with minor variations. Key insight: A common way to detect similarity between images is to produce embeddings of them and compute the dot product between embeddings. High dot product values indicate similar images. However, while this method detects large-scale similarities, it can fail to detect local ones. To detect a small area shared by two images, one strategy is to split apart their embeddings, compute the dot product between the pieces, and look for high values. How it works: The authors (i) trained image generators, (ii) generated images, and (iii) produced embeddings of those images as well as the training sets. They (iv) broke the embeddings into chunks and (v) detected duplications by comparing embeddings of the generated images with those of the training images.
Results: For each generated image, the authors found the 20 most similar images in the training set (that is, those whose fragmented embeddings yielded the highest dot products). Inspecting those images, they determined that the diffusion model sometimes copied elements from the training set. They plotted histograms of the similarity between images within a training set and the similarity between training images and generated images. The more the two histograms overlapped, the fewer the replications they expected to find. Both histograms and visual inspection indicated that models trained on smaller datasets contained more replications. However, on tests with Stable Diffusion, 1.88 percent of generated images had a similarity score greater than 0.5. Above that threshold, the authors observed obvious replications — despite that model’s pretraining on a large dataset. Why it matters: Does training an image generator on artworks without permission from the copyright holder violate the copyright? If the image generator literally copies the work, then the answer would seem to be “yes.” Such issues are being tested in court. This work moves the discussion forward by proposing a more sensitive measure of similarity between training and generated images. We're thinking: Picasso allegedly said that good artists borrow while great artists steal. . . .
Work With Andrew Ng
AI/ML Researcher/Engineer: Esteam seeks an artificial intelligence and machine learning engineer responsible for end-to-end ownership and scaling of its natural language processing, voice recognition, generative, and large language models. The ideal candidate has a clear understanding of deep learning, graphical models, reinforcement learning, computer perception, natural language processing, and data representation. Apply here
Customer Success Engineer: Landing AI seeks an engineer to build the foundation of the customer success function and handle account management inquiries, renewals, implementation/services, technical support, customer education, and operations. The ideal candidate is customer-oriented and experienced in the artificial intelligence/machine learning industry. Apply here
Fullstack (Backend) Founding Engineer: Kula seeks a fullstack engineer to join our early-stage startup. The ideal candidate is a hands-on technical leader willing to roll up their sleeves and lead the development of our backend, API, and overall architecture, and should have a clear understanding of how to architect and build the backend to support our mobile MVP. Apply here
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|


.jpg?upscale=true&width=1200&upscale=true&name=The%20Batch%20ads%20and%20exclusive%20banners%20(9).jpg)

