Dear friends,
There are many great applications to be built on top of large language models, and the overhead of doing so may be lower than you think. Sometimes, I've spent all day on a weekend developing ideas only to find that I've spent less than $0.50.
Given the low cost of keeping me busy all day, It might not surprise you to find that the cost of scaling up a business based on a large language model (LLM) can be quite inexpensive. As a back-of-the-envelope calculation, let’s say:
Then it costs around $0.08 to generate enough text to keep someone busy for an hour.
Here are some ways to think about this when it comes to automating or assisting a person’s work task:
On the flip side:
Please don’t use my back-of-the-envelope calculation for any significant business decisions, and do carry out your own calculations with careful assumptions specific to your project. But if you haven’t stepped through such a calculation before, the takeaway is that LLMs are actually quite inexpensive to use.
Granted, some models (like one version of GPT-4, at 15-30x the cost used in the calculation, leading to a cost of $1.80 instead of $0.08) are much more expensive. If your application requires a more capable model, then the calculation does change. But I’m optimistic that prices will come down over time, and these are all wonderful tools to have in your toolbox.
Keep learning! Andrew
P.S. I’ve noticed that most LLM providers don’t have transparent pricing. If you work at an LLM provider, I hope you’ll consider urging your company to list prices on its website.
News
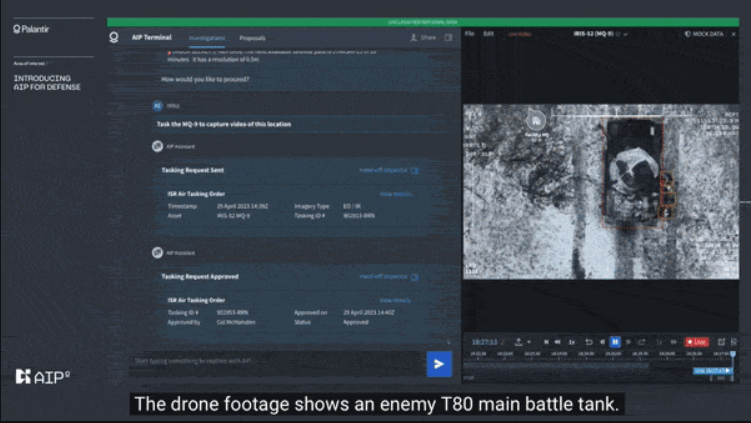
Battlefield ChatLarge language models may soon help military analysts and commanders make decisions on the battlefield.
Behind the news: Military forces are experimenting with AI for executing combat tactics.
Why it matters: At its best, this system could help military authorities identify threats sooner and streamline their responses, enabling them to outmaneuver their enemies. On the other hand, it represents a significant step toward automated warfare.
OpenAI Gears Up for BusinessReporters offered a behind-the-scenes look at OpenAI’s year-long effort to capitalize on its long-awaited GPT-4. What’s new: The company built a sales team and courted corporate partners in advance of launching its latest large language model, The Information reported.
Path to profit: In 2015, OpenAI started as a nonprofit research lab dedicated to transparency. In 2019, it launched a profit-seeking subsidiary to fund its research. In a series of deals between 2019 and 2023, Microsoft invested upward of $13 billion in exchange for 49 percent of OpenAI’s profit and right of first refusal to commercialize its technology. Yes, but: Observers have criticized both the company’s pivot to profit and its shift away from transparency. In a March interview, OpenAI’s co-founder Ilya Sutskever defended the organization’s secrecy, claiming it was necessary for safety as AI becomes more powerful. Why it matters: OpenAI saw generative AI’s commercial potential before ChatGPT sparked investments around the globe. That foresight could pay off handsomely, as the company forecasted revenue of $200 million this year and $1 billion by 2024.
A MESSAGE FROM DEEPLEARNING.AI
Are you ready to leverage AI for projects that can make a positive impact on public health, climate change, and disaster management? Pre-enroll in AI for Good and learn how!
Language Models in Lab CoatsSpecialized chatbots are providing answers to scientific questions. What’s new: A new breed of search engines including Consensus, Elicit, and Scite use large language models to enable scientific researchers to find and summarize significant publications, Nature reported. How it works: The models answer text questions by retrieving information from databases of peer-reviewed scientific research.
Yes, but: These tools may struggle with sensitive or fast-moving fields. For example, in response to the question, “Do vaccines cause autism?”, pediatrician Meghan Azad at the University of Manitoba found that Consensus returned a paper that focused on public opinion rather than scientific research. Clémentine Fourrier, who evaluates language models at HuggingFace, said that searching for machine learning papers via Elicit often brought up obsolete results. Why it matters: Search engines that rank and summarize relevant research can save untold hours for scientists, students, and seekers of knowledge in general. With continued improvement, they stand to accelerate the pace of progress.
Don’t Steal My StyleAsked to produce “a landscape by Thomas Kinkade,” a text-to-image generator fine-tuned on the pastoral painter’s work can mimic his style in seconds, often for pennies. A new technique aims to make it harder for algorithms to mimic an artist’s style. What’s new: Shawn Shan and colleagues at University of Chicago unveiled Glaze, a tool that imperceptibly alters works of art to prevent machine learning models from learning the artist's style from them. You can download it here. Key insight: Art style depends on many factors (color, shape, form, space, texture, and others). Some styles tend not to blend easily. For instance, a portrait can’t show both the sharp edges of a photograph and the oil-paint strokes of Vincent Van Gogh. Trained models have encountered few, if any, such blends, so they tend not to be able to mimic them accurately. But the ability of text-to-image generators to translate images into a different style (by prompting them with words like “. . . in the style of Van Gough”) makes it possible to alter a photorealistic portrait imperceptibly to make some pixels more like an oil painting (or vice-versa). Fine-tuned on such alterations, a text-to-image generator that’s prompted to imitate them will produce an incoherent blend that differs notably from the original style. How it works: Glaze makes an artist’s images more similar to images of a very different style. The difference derails image generators while being imperceptible to the human eye.
Results: The authors fine-tuned Stable Diffusion on Glaze-modified works by 13 artists of various styles and historical periods. Roughly 1,100 artists evaluated groups of four original and four mimicked works and rated how well Glaze protected an artist’s style (that is, how poorly Stable Diffusion mimicked the artist). 93.3 percent of evaluators found that Glaze successfully protected the style, while 4.6 percent judged that a separate Stable Diffusion fine-tuned on unmodified art was protective. Yes, but: It’s an open question whether Glaze works regardless of the combination of models used to produce embeddings, perform style transfer, and generate images. The authors’ tests were limited in this regard. Why it matters: As AI extends its reach into the arts, copyright law doesn’t yet address the use of creative works to train AI systems. Glaze enables artists to have a greater say in how their works can be used — by Stable Diffusion, at least. We’re thinking: While technology can give artists some measure of protection against stylistic appropriation by AI models, ultimately society at large must resolve questions about what is and isn't fair. Thoughtful regulation would be better than a cat-and-mouse game between artists and developers.
Work With Andrew Ng
AI/ML Researcher/Engineer: Esteam seeks a machine learning engineer responsible for end-to-end ownership and scaling of its natural language processing, voice recognition, generative, and large language models. The ideal candidate has a clear understanding of deep learning, graphical models, reinforcement learning, computer perception, natural language processing, and data representation. Apply here
Full stack (Backend) Founding Engineer: Kula seeks a full stack engineer to join our early-stage startup. The ideal candidate is a hands-on technical leader willing to roll up their sleeves and lead the development of our backend, API, and overall architecture. They should have a clear understanding of how to architect and build the backend to support our mobile MVP. Apply here
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|
.png?upscale=true&width=1200&upscale=true&name=January%2025%2c%202023%20(2).png)
.gif?upscale=true&width=1200&upscale=true&name=ezgif.com-optimize%20(16).gif)
.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20ads%20and%20exclusive%20banners%20(17).png)

