Dear friends,
Machine learning development is an empirical process. It’s hard to know in advance the result of a hyperparameter choice, dataset, or prompt to a large language model (LLM). You just have to try it, get a result, and decide on the next step. Still, understanding how the underlying technology works is very helpful for picking a promising direction. For example, when prompting an LLM, which of the following is more effective?
Prompt 2: [Problem/question description] Explain your reasoning and then state the answer.
The image above illustrates this difference using a question with one right answer. But similar considerations apply when asking an LLM to make judgment calls when there is no single right answer; for example, how to phrase an email, what to say to someone who is upset, or the proper department to route a customer email to.
Keep learning! Andrew
P.S. Our short course on fine-tuning LLMs is now available! As I wrote last week, many developers are not only prompting LLMs but also fine-tuning them — that is, taking a pretrained model and training it further on their own data. Fine-tuning can deliver superior results, and it can be done relatively inexpensively. In this course, Sharon Zhou, CEO and co-founder of Lamini (disclosure: I’m a minor shareholder) shows you how to recognize when fine-tuning can be helpful and how to do it with an open-source LLM. Learn to fine-tune your own models here.
News
News Outlet Challenges AI DevelopersThe New York Times launched a multi-pronged attack on the use of its work in training datasets. What’s new: The company updated its terms of service to forbid use of its web content and other data for training AI systems, Adweek reported. It’s also exploring a lawsuit against OpenAI for unauthorized use of its intellectual property, according to NPR. Meanwhile, The New York Times backed out of a consortium of publishers that would push for payment from AI companies.
Behind the news: Earlier this month, 10 press and media organizations including Agence France-Presse, Associated Press, and stock media provider Getty Images signed an open letter that urges regulators to place certain restrictions on AI developers. The letter calls for disclosure of training datasets, labeling of model outputs as AI-generated, and obtaining consent of copyright holders before training a model on their intellectual property. The letter followed several ongoing lawsuits that accuse AI developers of appropriating data without proper permission or compensation. Why it matters: Large machine learning models rely on training data scraped from the web as well as other freely available sources. Text on the web is sufficiently plentiful that losing a handful of sources may not affect the quality of trained models. However, if the norms were to shift around using scraped data to train machine learning models in ways that significantly reduced the supply of high-quality data, the capabilities of trained models would suffer. We’re thinking: Society reaps enormous rewards when people are able to learn freely. Similarly, we stand to gain incalculable benefits by allowing AI to learn from information available on the web. An interpretation of copyright law that blocks such learning would hurt society and derail innovation. It’s long past time to rethink copyright for the age of AI.
Defcon Contest Highlights AI SecurityHackers attacked AI models in a large-scale competition to discover vulnerabilities. What’s new: At the annual Defcon hacker convention in Las Vegas, 2,200 people competed to break guardrails around language models, The New York Times reported. The contest, which was organized by AI safety nonprofits Humane Intelligence and SeedAI and sponsored by the White House and several tech companies, offered winners an Nvidia RTX A6000 graphics card.
Behind the news: Large AI developers often test their systems by hiring hackers called “red teams,” a term used by the United States military to represent enemy forces in Cold War-era war games, to attack them.
Why it matters: The security flaws found in generative AI systems are distinctly different from those in other types of software. Enlisting hackers to attack systems in development is essential in sniffing out flaws in conventional software. It’s a good bet for discovering deficiencies in AI models as well. We’re thinking: Defcon attracts many of the world’s most talented hackers — people who have tricked ATMs into dispensing cash and taken over automobile control software. We feel safer knowing that this crowd is on our side.
A MESSAGE FROM DEEPLEARNING.AI
Join "Finetuning Large Language Models," a new short course that teaches you how to finetune open source models on your own data. Enroll today and get started
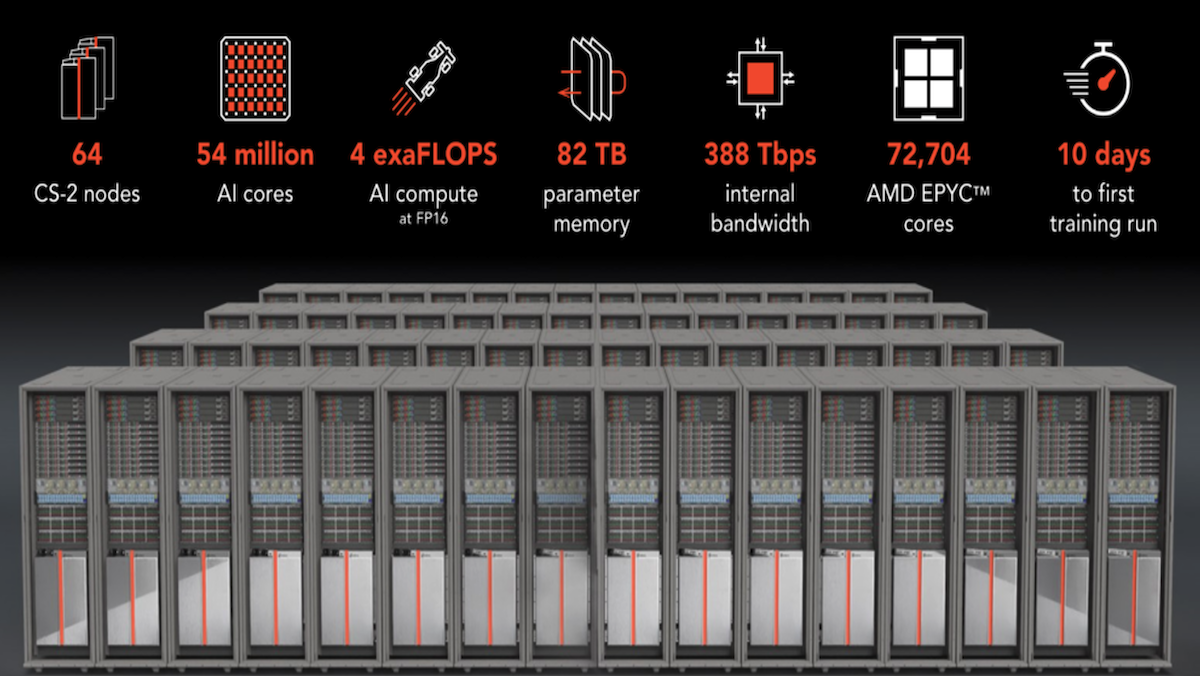
AI Chip Challenger Gains TractionAn upstart supplier of AI chips secured a major customer. What’s new: Cerebras, which competes with Nvidia in hardware for training large models, signed a $100 million contract with Abu Dhabi tech conglomerate G42. The deal is the first part of a multi-stage plan to build a network of supercomputers. How it works: The deal covers the first three of nine proposed systems. The first, Condor Galaxy 1 (CG-1), is already up and running in Santa Clara, California. CG-2 and CG-3 are slated to open in early 2024 in Austin, Texas and Asheville, North Carolina. Cerebras and G42 are in talks to build six more by the end of 2024. G42 plans to use the network to supply processing power primarily to healthcare and energy companies
Behind the news: Nvidia accounts for 95 percent of the market for GPUs used in machine learning — a formidable competitor to Cerebras and other vendors of AI chips. Despite Nvidia’s position, though, there are signs that it’s not invincible.
Why it matters: The rapid adoption of generative AI is fueling demand for the huge amounts of processing power required to train and run state-of-the-art models. In practical terms, Nvidia is the only supplier of tried-and-true AI chips for large-scale systems. This creates a risk for customers who need access to processing power and an opportunity for competitors who can satisfy some of that demand. We’re thinking: As great as Nvidia’s products are, a monopoly in AI chips is not in anyone’s best interest. Cerebras offers an alternative for training very large models. Now cloud-computing customers can put it to the test.
Vision Transformers Made ManageableVision transformers typically process images in patches of fixed size. Smaller patches yield higher accuracy but require more computation. A new training method lets AI engineers adjust the tradeoff. What's new: Lucas Beyer and colleagues at Google Research trained FlexiViT, a vision transformer that allows users to specify the desired patch size. Key insight: Vision transformers turn each patch into a token using two matrices of weights, whose values describe the patch’s position and appearance. The dimensions of these matrices depend on patch size. Resizing the matrices enables a transformer to use patches of arbitrary size. How it works: The authors trained a standard vision transformer on patches of random sizes between 8x8 and 48x48 pixels. They trained it to classify ImageNet-21K (256x256 pixels).
Results: The authors compared FlexiVit to two vanilla vision transformers, ViT-B/16 and ViT-B/30, trained on ImageNet-21k using patch sizes of 16x16 and 30x30 respectively. Given patches of various sizes, the vanilla vision transformers’ position and appearance matrices adjusted in the same manner as FlexiViT’s. FlexiViT performed consistently well across patch sizes, while the models trained on a fixed patch size performed well only with that size. For example, given 8x8 patches, FlexiViT achieved 50.2 percent precision; ViT-B/16 achieved 30.5 percent precision, and ViT-B/30 achieved 2.9 percent precision. Given 30x30 patches, FlexiViT achieved 46.6 percent precision, ViT-B/16 achieved 2.4 percent precision, and ViT-B/30 achieved 47.1 percent precision. Why it matters: The processing power available often depends on the project. This approach makes it possible to train a single vision transformer and tailor its patch size to accommodate the computation budget at inference. We're thinking: Unlike text transformers, for which turning text into a sequence of tokens is relatively straightforward, vision transformers offer many possibilities for turning an image into patches and patches into tokens. It’s exciting to see continued innovation in this area.
Work With Andrew Ng
Join the teams that are bringing AI to the world! Check out job openings at DeepLearning.AI, AI Fund, and Landing AI.
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|
.png?upscale=true&width=1200&upscale=true&name=January%2025%2c%202023%20(18).png)
-3.gif?upscale=true&width=1200&upscale=true&name=ezgif.com-optimize%20(4)-3.gif)


.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20ads%20and%20exclusive%20banners%20(51).png)