Dear friends,
The rise of cloud-hosted AI software has brought much discussion about the privacy implications of using it. But I find that users, including both consumers and developers building on such software, don’t always have a sophisticated framework for evaluating how software providers store, use, and share their data. For example, does a company’s promise “not to train on customer data” mean your data is private?
These levels may seem clear, but there are many variations within a given level. For instance, a promise not to train on your data can mean different things to different companies. Some forms of generative AI, particularly image generators, can replicate their training data, so training a generative AI algorithm on customer data may run some risk of leaking it. On the other hand, tuning a handful of an algorithm’s hyperparameters (such as learning rate) to customer data, while technically part of the training process, is very unlikely to result in any direct data leakage. So how the data is used in training will affect the risk of leakage.
Similarly, the Limited Access level has its complexities. If a company offers this level of privacy, it’s good to understand exactly under what circumstances its employees may look at your data. And if they might look at your data, there are shades of gray in terms of how private the data remains. For example, if a limited group of employees in a secure environment can see only short snippets that have been disassociated from your company ID, that’s more secure than if a large number of employees can freely browse your data.
Over the past decade, cloud hosted SaaS software has gained considerable traction. But some customers insist on running on-prem solutions within their own data centers. One reason is that many SaaS providers offer only No Guarantees or No Outside Exposure, but many customers’ data is so sensitive that it requires Limited Access.
I've been delighted to see that here, AI can help. Daphne Li, CEO of Commonsense Privacy (disclosure: a portfolio company of AI Fund), is using large language models to help companies systematically evaluate, and potentially improve, their privacy policies as well as keep track of global regulatory changes. In the matter of privacy, as in other areas, I hope that the title of my TED AI talk — “AI Isn’t the Problem, It’s the Solution” — will prove to be true.
Keep learning! Andrew
P.S. Check out our new short course with Amazon Web Services on “Serverless LLM Apps With Amazon Bedrock,” taught by Mike Chambers. A serverless architecture enables you to quickly deploy applications without needing to set up and manage compute servers to run your applications on, often a full-time job in itself. In this course, you’ll learn how to implement serverless deployment by building event-driven systems. We illustrate this approach via an application that automatically detects incoming customer inquiries, transcribes them with automatic speech recognition, summarizes them with an LLM using Amazon Bedrock, and runs serverless with AWS Lambda. We invite you to enroll here!
News
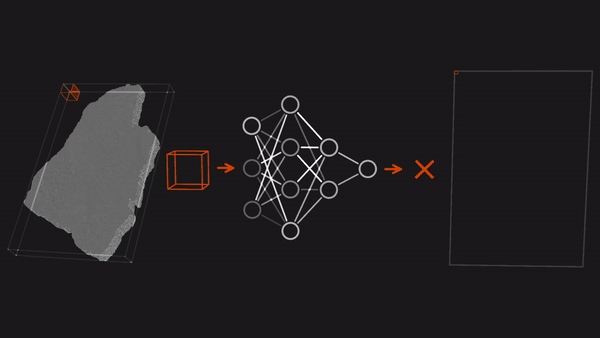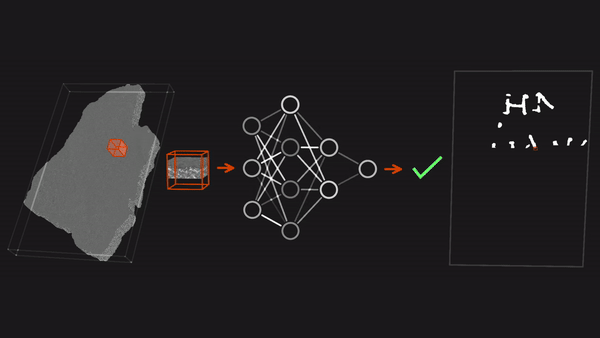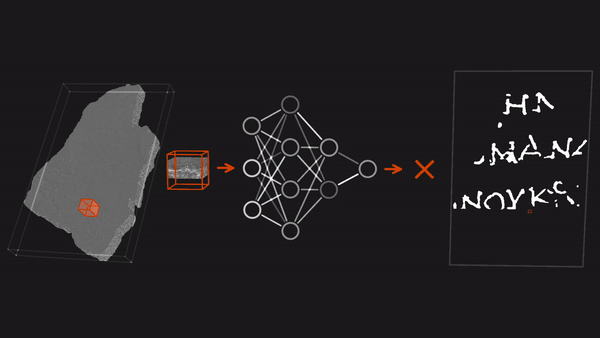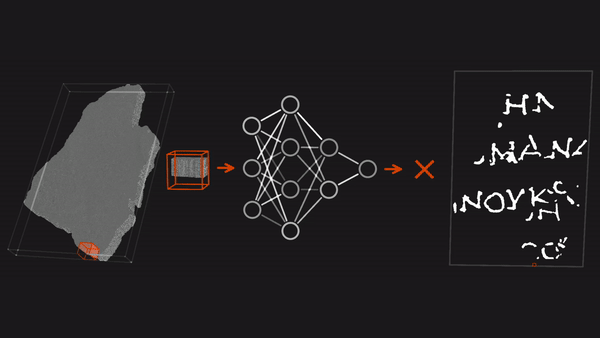
Ancient Scrolls RecoveredThree researchers decoded scrolls that had gone unread since they were turned into charcoal by the eruption of Mount Vesuvius in the year 79. What’s new: Youssef Nader, Luke Farritor, and Julian Schilliger used neural networks to win the $700,000 grand prize in the Vesuvius Challenge, a competition to translate charred papyrus scrolls found in the ruins of a villa at the Roman town of Herculaneum in southern Italy. How it works: The volcanic eruption covered Herculaneum in ash. It also transformed into carbon the papyrus scrolls, which originally would have unrolled to lengths as long as 30 feet.
Behind the news: The Vesuvius Challenge launched in March 2023 with funding provided by GitHub CEO Nat Friedman.
Why it matters: The winning team’s achievement testifies to the ability of deep learning to help solve difficult problems. And their work may have broader significance: Recovering the entire Herculaneum library could provide insights into literature, philosophy, history, science, and art at the time of Caesar. We’re thinking: University of Kentucky computer scientist Brent Seales, who helped design the contest as well as pioneering the use of medical imaging and machine learning to read ancient texts, reckons that over 1,000 teams worked on the problem, amounting to 10 person-years and two compute-years. It's a great example of the power of global collaboration and open resources — central facets of the AI community — to find solutions to hard problems.
U.S. Restricts AI RobocallsThe United States outlawed unsolicited phone calls that use AI-generated voices. What’s new: The Federal Communications Commission ruled that the current legal restriction on voice communications that use “artificial or prerecorded voices” covers AI-powered voice generation. The ruling followed an incident in which calls that featured the cloned voice of U.S. President Biden were delivered with the apparent intent of interfering with an election. How it works: The ruling interprets the 1991 Telephone Consumer Protection Act, which controls automated calls, or robocalls. The law gives state attorneys general the power to prosecute robocallers. The FCC had proposed the move in January.
Behind the news: In January, two days before a presidential primary election, thousands of members of the Democratic Party in the state of New Hampshire received phone calls in which a cloned voice of President Biden, who is a Democrat, urged them not to vote in a presidential primary election. The call used voice cloning software from Eleven Labs, according to researchers cited by Wired. New Hampshire investigated the calls as a case of illegal voter suppression. It traced them to two telecommunications companies in the state of Texas and issued cease-and-desist orders and subpoenas to both firms. One, Lingo Telecom, said it is cooperating with federal and state investigators. Why it matters: For all its productive uses, generative AI offers fresh opportunities to scammers to deceive their marks into handing over things of value. Voice cloning can elevate their appeal by simulating personal, business, political, and other relationships. Election officials are especially concerned about AI’s potential to influence voting, especially as we enter a year that will see over 100 elections in seven of the 10 most populous nations. We’re thinking: The question of how to safeguard elections against manipulations like the Biden robocall is an urgent one. Devising a tamper-resistant watermark that identifies generated output would discourage misuse. However, providers will have a financial incentive not to apply such watermarks unless regulators require it.
A MESSAGE FROM DEEPLEARNING.AI
In our latest course, built in collaboration with Amazon Web Services, you’ll learn to deploy applications based on large language models using a serverless architecture. This enables rapid deployment and liberates you from the complexities of managing and scaling infrastructure. Start today!
GPU Data Centers Strain Grid PowerThe AI boom is taxing power grids and pushing builders of data centers to rethink their sources of electricity. What’s new: New data centers packed with GPUs optimized for AI workloads are being approved at a record pace, The Information reported. The extreme energy requirements of such chips are pushing builders to place data centers near inexpensive power sources, which may be far away from where users live. How it works: The coming generation of GPU data centers promises to supply processing power for the burgeoning AI era. But builders aren’t always able to find electricity to run them.
What they’re saying: “We still don’t appreciate the energy needs of [AI] technology. There's no way to get there without a breakthrough.” — Sam Altman, CEO, OpenAI, on January 16, 2024, quoted by Reuters. Behind the news: Data centers alone account for 1 to 1.5 percent of global demand for electricity. It’s unclear how much of that figure is attributable to AI, but the share is likely to grow. Why it matters: The world needs innovation in both energy resources and power-efficient machine learning. The dawning era of pervasive AI brings with it the challenge of producing energy to develop and deploy the technology, which can contribute to pollution that disrupts ecosystems and accelerates climate change. Fortunately, AI can shrink the environmental footprint of some energy-intensive activities; for example, searching the web for information generates far less CO2 emissions than driving to a library. We’re thinking: Climate change is a slow-motion tragedy. We must push toward AI infrastructure that uses less energy (for example, by using more efficient algorithms or hardware) and emits less carbon (for example, by using renewable sources of energy). That said, concentrating computation in a data center creates a point of significant leverage for optimizing energy usage. For example, it’s more economical to raise the energy efficiency of 10,000 servers in a data center than 10,000 PCs that carry out the same workload in 10,000 homes.
Better Images, Less TrainingThe longer text-to-image models train, the better their output — but the training is costly. Researchers built a system that produced superior images after far less training. What's new: Independent researcher Pablo Pernías and colleagues at Technische Hochschule Ingolstadt, Université de Montréal, and Polytechnique Montréal built Würstchen, a system that divided the task of image generation between two diffusion models. Diffusion model basics: During training, a text-to-image generator based on diffusion takes a noisy image and a text embedding. The model learns to use the embedding to remove the noise in successive steps. At inference, it produces an image by starting with pure noise and a text embedding, and removing noise iteratively according to the text embedding. A variant known as a latent diffusion model uses less processing power by removing noise from a noisy image embedding instead of a noisy image. Key insight: A latent diffusion model typically learns to remove noise from an embedding of an input image based solely on a text prompt. It can learn much more quickly if, in addition to the text prompt, a separate model supplies a smaller, noise-free version of the image embedding. Working as a system, the two models can learn their tasks in a fraction of the usual time. How it works: Würstchen involves three components that required training: the encoder-decoder from VQGAN, a latent diffusion model based on U-Net, and another latent diffusion model based on ConvNeXt. The authors trained the models separately on subsets of LAION-5B, which contains matched images and text descriptions scraped from the web.
Results: The authors compared Würstchen (trained on subsets of LAION-5B for 25,000 GPU hours) to Stable Diffusion 2.1 (trained on subsets of LAION-5B for 200,000 GPU hours). The authors generated images based on captions from MS COCO (human-written captions of pictures scraped from the web) and Parti-prompts (human-written captions designed to reflect common prompts for generative models). They asked 90 people which output they preferred. The judges expressed little preference regarding renderings of MS COCO captions: They chose Würstchen 41.3 percent of the time, Stable Diffusion 40.6 percent of the time, and neither 18.1 percent of the time. However, presented with the results of Parti-prompts, they preferred Würstchen 49.5 percent of the time, Stable Diffusion’s 32.8 percent of the time, and neither 17.7 percent of the time. Why it matters: Training a latent diffusion model to denoise smaller embeddings accelerates training, but this tends to produce lower-quality images. Stacking two diffusion models — one to generate smaller embeddings, and the other to generate larger embeddings based on the smaller ones — enabled Würstchen to match or exceeded the output quality of models with large embeddings, while achieving the training speed of models with small embeddings. We're thinking: Stacking models in this fashion could be useful in training video generators. They could use a speed boost because video is much more data-intensive than still images.
A MESSAGE FROM FOURTHBRAIN
Join us for an intensive three-week workshop where you’ll learn to operationalize large language models at scale, from learning advanced retrieval augmented generation (RAG) to deploying multimodal applications on the cloud. Register today!
Work With Andrew Ng
Join the teams that are bringing AI to the world! Check out job openings at DeepLearning.AI, AI Fund, and Landing AI.
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|
.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20top%20banners%20(5).png)