Dear friends,
Do large language models understand the world? As a scientist and engineer, I’ve avoided asking whether an AI system “understands” anything. There’s no widely agreed-upon, scientific test for whether a system really understands — as opposed to appearing to understand — just as no such tests exist for consciousness or sentience, as I discussed in an earlier letter. This makes the question of understanding a matter of philosophy rather than science. But with this caveat, I believe that LLMs build sufficiently complex models of the world that I feel comfortable saying that, to some extent, they do understand the world.
During training, the network saw only sequences of moves. It wasn’t explicitly told that these were moves on a square, 8x8 board or the rules of the game. After training on a large dataset of such moves, it did a decent job of predicting what the next move might be.
While this study used Othello, I have little doubt that LLMs trained on human text also build world models. A lot of “emergent” behaviors of LLMs — for example, the fact that a model fine-tuned to follow English instructions can follow instructions written in other languages — seem very hard to explain unless we view them as understanding the world.
AI has wrestled with the notion of understanding for a long time. Philosopher John Searle published the Chinese Room Argument in 1980. He proposed a thought experiment: Imagine an English speaker alone in a room with a rulebook for manipulating symbols, who is able to translate Chinese written on paper slipped under the door into English, even though the person understands no Chinese. Searle argued that a computer is like this person. It appears to understand Chinese, but it really doesn’t.
A common counterargument known as the Systems Reply is that, even if no single part of the Chinese Room scenario understands Chinese, the complete system of the person, rulebook, paper, and so on does. Similarly, no single neuron in my brain understands machine learning, but the system of all the neurons in my brain hopefully do. In my recent conversation with Geoff Hinton, which you can watch here, the notion that LLMs understand the world was a point we both agreed on.
Okay, back to coding.
Keep learning, Andrew
News
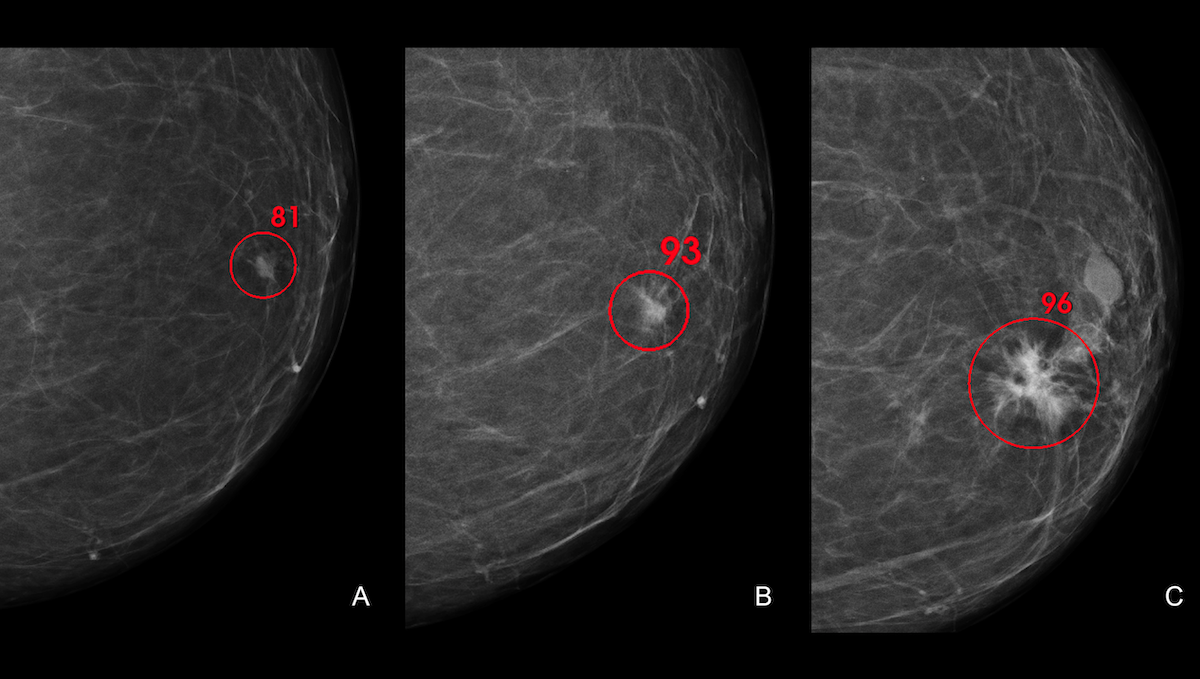
Rigorous Trial: AI Matches Humans in Breast Cancer DiagnosisA deep learning system detected breast cancer in mammograms as well as experienced radiologists, according to a landmark study. What’s new: Researchers at Lund University in Sweden conducted a randomized, controlled, clinical trial to determine whether an AI system could save radiologists’ time without endangering patients — purportedly the first study of AI’s ability to diagnose breast cancer from mammograms whose design met the so-called gold standard for medical tests. Their human-plus-machine evaluation procedure enabled radiologists to spend substantially less time per patient while exceeding a baseline for safety. How it works: The authors randomly divided 80,000 Swedish women into a control group and an experimental group.
Results: The AI-assisted diagnosis achieved a cancer detection rate of 6.1 per 1,000 patients screened, comparable to the control method and above an established lower limit for safety. The radiologists recalled 2.0 percent of the control group and 2.2 percent of the experimental group, and both the control and experimental groups showed the same false-positive rate of 1.5 percent. (The difference in recall rates coupled with the matching false-positive rate suggests that the AI method detected 20 percent more cancer cases than the manual method, though authors didn’t emphasize that finding.) Moreover, since approximately 37,000 patients were only examined by one radiologist, the results indicate that AI saved 44.3 percent of the examination workload without increasing the number of misdiagnosed patients. Yes, but: The authors’ method requires more study before it can enter clinical practice; for instance, tracking patients of varied genetic backgrounds. The authors are continuing the trial and plan to publish a further analysis after 100,000 patients have been enrolled for two years. Behind the news: Radiologists have used AI to help diagnose breast cancer since the 1980s (though that method is questionable.) A 2020 study by Google Health claimed that AI outperformed radiologists, but critics found flaws in the methodology. Why it matters: Breast cancer causes more than 600,000 deaths annually worldwide. This work suggests that AI can enable doctors to evaluate more cases faster, helping to alleviate a shortage of radiologists. Moreover, treatment is more effective the earlier the cancer is diagnosed, and the authors’ method caught more early than late ones. We’re thinking: Medical AI systems that perform well in the lab often fail in the clinic. For instance, a neural network may outperform humans at cancer diagnosis in a specific setting but, having been trained and tested on the same data distribution, isn’t robust to changes in input (say, images from different hospitals or patients from different populations). Meanwhile, medical AI systems have been subjected to very few randomized, controlled trials, which is considered the gold standard for medical testing. Such trials have their limitations, but they’re a powerful tool for bridging the gap between lab and clinic.
Robots Work the Drive-ThruChatbots are taking orders for burgers and fries — and making sure you buy a milkshake with them. What’s new: Drive-thru fast-food restaurants across the United States are rolling out chatbots to take orders, The Wall Street Journal reported. Reporter Joanna Stern delivers a hilarious consumer’s-eye view in an accompanying video. How it works: Hardee’s, Carl’s Jr., Checkers and Del Taco use technology from Presto, a startup that specializes in automated order-taking systems. The company claims 95 percent order completion and $3,000 in savings per month per store. A major selling point: Presto’s bot pushes bigger orders that yield $4,500 per month per store in additional revenue.
Behind the news: The fast-food industry is embracing AI to help out in the kitchen, too.
Yes, but: McDonald’s, the world’s biggest fast-food chain by revenue, uses technology from IBM and startup Apprente, which it acquired in 2019. As of early this year, the system achieved 80 percent accuracy — far below the 95 percent that executives had expected. Why it matters: In fast food, chatbots are continuing a trend in food service that began with Automat cafeterias in the early 1900s. Not only are they efficient at taking orders, apparently they’re more disciplined than typical employees when it comes to suggesting ways to enlarge a customer’s order (and, consequently, waist). We’re thinking: When humans aren’t around, order-taking robots order chips.
A MESSAGE FROM DEEPLEARNING.AI
Join our upcoming workshop with Weights & Biases and learn how to evaluate Large Language Model systems, focusing on Retrieval Augmented Generation (RAG) systems. Register now
The High Cost of Serving LLMsAmid the hype that surrounds large language models, a crucial caveat has receded into the background: The current cost of serving them at scale. What’s new: As chatbots go mainstream, providers must contend with the expense of serving sharply rising numbers of users, the Washington Post reported. The price of scaling: The transformer architecture, which is the basis of models like OpenAI’s ChatGPT, requires a lot of processing. Its self-attention mechanism is computation-intensive, and it gains performance with higher parameter counts and bigger training datasets, giving developers ample incentive to raise the compute budget.
Why it matters: Tech giants are racing to integrate large language models into search engines, email, document editing, and an increasing variety of other services. Serving customers may require taking losses in the short term, but winning in the market ultimately requires balancing costs against revenue.
Diffusion TransformedA tweak to diffusion models, which are responsible for most of the recent excitement about AI-generated images, enables them to produce more realistic output. What's new: William Peebles at UC Berkeley and Saining Xie at New York University improved a diffusion model by replacing a key component, a U-Net convolutional neural network, with a transformer. They call the work Diffusion Transformer (DiT). Diffusion basics: During training, a diffusion model takes an image to which noise has been added, a descriptive embedding (typically an embedding of a text phrase that describes the original image, in this experiment, the image’s class), and an embedding of the current time step. The system learns to use the descriptive embedding to remove the noise in successive time steps. At inference, it generates an image by starting with pure noise and a descriptive embedding and removing noise iteratively according to that embedding. A variant known as a latent diffusion model saves computation by removing noise not from an image but from an image embedding that represents it. Key insight: In a typical diffusion model, a U-Net convolutional neural network (CNN) learns to estimate the noise to be removed from an image. Recent work showed that transformers outperform CNNs in many computer vision tasks. Replacing the CNN with a transformer can lead to similar gains. How it works: The authors modified a latent diffusion model — Stable Diffusion — by putting a transformer at its core. They trained it on ImageNet in the usual manner for diffusion models.
Results: The authors assessed the quality of DiT’s output according to Fréchet Interception Distance (FID), which measures how the distribution of a generated version of an image compares to the distribution of the original (lower is better). FID improved depending on the processing budget: On 256-by-256-pixel ImageNet images, a small DiT with 6 gigaflops of compute achieved 68.4 FID, a large DiT with 80.7 gigaflops achieved 23.3 FID, and the largest DiT with 119 gigaflops achieved 9.62 FID. A latent diffusion model that used a U-Net (104 gigaflops) achieved 10.56 FID. Why it matters: Given more processing power and data, transformers achieve better performance than other architectures in numerous tasks. This goes for the authors’ transformer-enhanced diffusion model as well. We're thinking: Transformers continue to replace CNNs for many tasks. We’ll see if this replacement sticks.
Work With Andrew Ng
Join the teams that are bringing AI to the world! Check out job openings at DeepLearning.AI, AI Fund, and Landing AI.
Subscribe and view previous issues here.
Thoughts, suggestions, feedback? Please send to thebatch@deeplearning.ai. Avoid our newsletter ending up in your spam folder by adding our email address to your contacts list.
|
.png?upscale=true&width=1200&upscale=true&name=January%2025%2c%202023%20(16).png)


.png?upscale=true&width=1200&upscale=true&name=The%20Batch%20ads%20and%20exclusive%20banners%20(49).png)